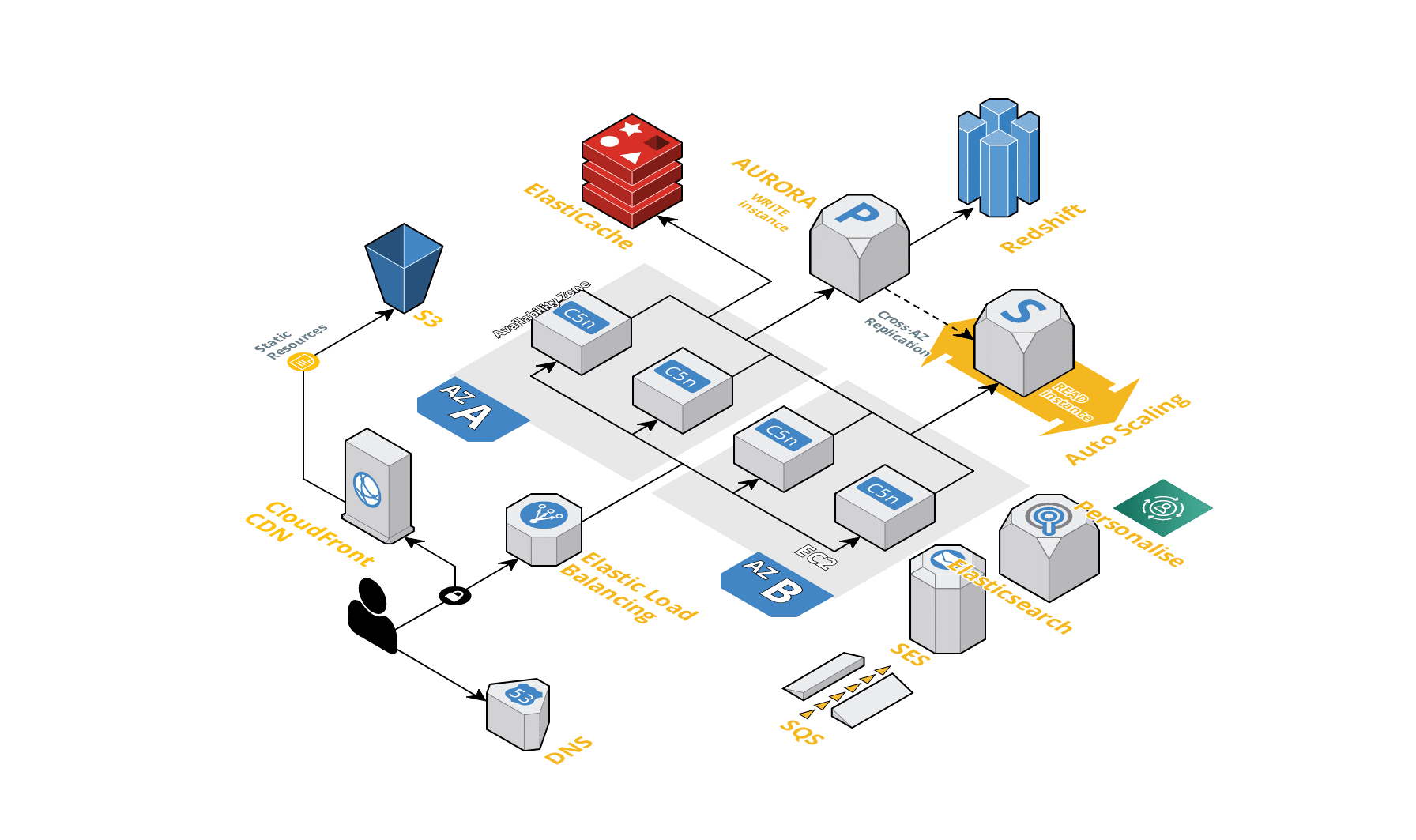
KTOWN4U Case Study: 글로벌 확장성과 개인화 서비스 최적화
케이타운포유는 급성장 중인 K-Pop 및 한류 상품을 글로벌 판매하는 이커머스 서비스를 제공하는 회사로 2002년 서비스를 시작한 이래 200개국, 6개 언어로 500만 회원, 5,000여 개 팬클럽을 대상으로 서비스하고 있습니다. 케이타운포유는 B2B에서 B2C로 전환 후 2021년 매출액 2,000억을 돌파하며 짧은 기간에 15배에 달하는 성장을 하였습니다.

케이타운포유는 사용자서비스, 운영시스템, 물류시스템(WMS) 등의 시스템을 개발, 운영하고 있으며, 이를 위해 모든 시스템을 AWS 클라우드에서 구축/운영하고 있습니다. 2022년에 많은 버그를 해결함과 동시에 트래픽 수용을 위한 개선을 이뤘고, 2023년에는 상품구조 개선, 물류시스템 개선 및 고도화, 거대 모놀리식 레거시 시스템을 MSA 구조로 변경 진행 중에 있습니다.
당면 과제
케이타운포유는 비즈니스가 성장하면서 글로벌 사용자와 데이터가 증가하면서 자체 구축한 온프레미스 환경은 물리적인 한계로 안정적인 서비스를 제공하는 데 어려움이 있었습니다. 특히, 유명 K팝 아티스트의 앨범이나 한류 굿즈가 출시되거나 이벤트를 진행할 때 대규모 트래픽이 발생하여 서버가 다운되는 이슈가 있었습니다. 온프레미스 환경에서는 서버 자원 관리가 용이하지 않고 인프라를 탄력적으로 운영할 수 없었습니다. 케이타운포유는 글로벌 웹 커머스 플랫폼으로 더욱 도약하기 위해 인프라 관리 편의성과 접근성, 갑자기 급증하는 트래픽에 빠르게 대응할 수 있는 확장성과 안정성 보장, 웹 플랫폼의 고속 전송 네트워크 콘텐츠, 전 세계 고객의 경험 데이터를 기반으로 빅데이터 분석을 적용한 개인화 서비스, 마케팅 및 비즈니스 인사이트를 위한 데이터웨어하우스(DW)를 고려하게 되었습니다.
Amazon CloudFront
KTOWN4U의 CloudFront 도입 이유
콘텐츠 전송 네트워크(CDN) 서비스인 Amazon CloudFront를 도입하여 높은 전송 속도로 안전하게 콘텐츠를 전송할 수 있게 네트워크를 구축했습니다.
Amazon CloudFront란?
개발자 친화적 환경에서 짧은 지연과 빠른 전송 속도로 데이터, 동영상, 애플리케이션 및 API를 전세계 고객에게 안전하게 전송하는 고속 컨텐츠 전송 네트워크(CDN) 서비스
CloudFront는 CDN 서비스 이외에도 기본 보안 기능(Anti-DDoS)을 제공
CDN이란?
- 컨텐츠를 효율적으로 전달하기 위해 여러 노드를 가진 네트워크에 데이터를 저장하여 제공하는 시스템
- 인터넷 서비스 제공자(ISP)에 직접 연결되어 데이터를 전송하므로, 컨텐츠 병목을 피할 수 있다는 장점
- 특징
- 웹 페이지, 이미지, 동영상 등의 컨텐츠를 본래 서버에서 받아와 캐싱
- 해당 컨텐츠에 대한 요청이 들어오면 캐싱해 둔 컨텐츠를 제공
- 컨텐츠를 제공하는 서버와 실제 요청 지점 간의 지리적 거리가 매우 먼 경우 or 통신 환경이 안 좋은 경우 → 요청 지점의 CDN을 통해 빠르게 컨텐츠를 제공
- 서버의 요청이 필요 없으므로 서버의 부하를 낮추는 효과
CloudFront 동작 방식
💡 엣지 로케이션: 컨텐츠가 캐싱되고 유저에게 제공되는 지점. AWS가 CDN을 제공하기 위해서 만든 서비스인 CloudFront의 캐시 서버 (데이터 센터의 전 세계 네트워크)
AWS 백본 네트워크를 통해 컨텐츠를 가장 효과적으로 서비스할 수 있는 엣지로 각 사용자 요청을 라우팅하여 컨텐츠 배포 속도를 높임.
컨텐츠가 엣지 로케이션에 없는 경우
- CloudFront는 컨텐츠의 최종 버전에 대한 소스로 지정된 오리진(S3 버킷, MediaPackage 채널, http 서버 등)에서 컨텐츠를 검색
- 컨텐츠를 제공하는 근원에서 제공받아 전달
컨텐츠가 엣지 로케이션에 있는 경우
- 바로 전달
데이터 전달 과정
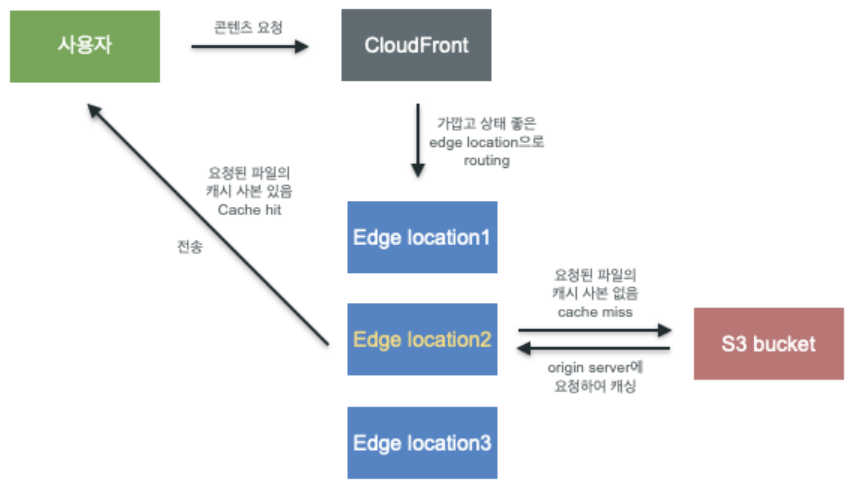
- 클라이언트로부터 Edge Server로의 요청이 발생
- Edge Server는 요청이 발생한 데이터에 대하여 캐싱 여부를 확인
- 사용자의 근거리에 위치한 Edge Server 중 캐싱 데이터가 존재한다면 사용자의 요청에 맞는 데이터를 응답합니다. 사용자의 요청에 적합한 데이터가 캐싱되어 있지 않은 경우 Orgin Server로 요청이 포워딩됨.
- 요청받은 데이터에 대해 Origin Server에서 획득한 후 Edge Server에 캐싱 데이터를 생성하고, 클라이언트로 응답이 발생
CloudFront 장점
- AWS 네트워크를 사용하면 사용자의 요청이 반드시 통과해야 하는 네트워크의 수가 줄어들어 성능이 향상됨.
- 파일의 첫 바이트를 로드하는 데 걸리는 지연 시간이 줄어들고 데이터 전송 속도가 빨라짐.
- 파일(객체)의 사본이 전 세계 여러 엣지 로케이션에 유지(또는 캐시)되므로 안정성과 가용성이 향상됨.
- 보안성이 향상됨.
- 오리진 서버에 대한 종단 간 연결의 보안이 보장됨. (https)
- 서명된 URL 및 쿠키 사용 옵션으로 자체 사용자 지정 오리진에서 프라이빗 콘텐츠를 제공하도록 할 수 있음.
결론
- 케이타운포유는 Amazon CloudFront를 도입해 글로벌 사용자가 콘텐츠에 신속하고 안정적으로 접근할 수 있도록 인프라를 구축함.
- 특히, 글로벌 이벤트와 대규모 트래픽 스파이크에 대비해 성능을 최적화.
- CloudFront는 CDN을 통해 엣지 로케이션에서 캐시된 콘텐츠를 제공, 네트워크 병목을 줄이고 서버 부하를 효과적으로 분산.
- 이를 통해 고속 전송과 보안성을 확보, 대규모 트래픽 시에도 안정적인 서비스 유지.
- 결과적으로, CloudFront는 케이타운포유가 글로벌 시장에서 서비스 품질을 유지하고, 고객 만족도를 높이는 중요한 요소로 자리잡음.
Amazon S3
KTOWN4U의 S3 도입 이유
무제한에 가까운 스토리지인 Amazon Simple Storage Service (Amazon S3)를 추가하여 이미지 콘텐츠, 대용량 로그를 저장 및 분석에 사용했습니다.
S3란? (Simple Storage Service)
- 업계 최고의 확장성과 데이터 가용성 및 보안과 성능을 제공하는 온라인 오브젝트 스토리지 서비스. 쉽게 말하자면 데이터를 온라인으로 오브젝트 형태로 저장하는 서비스이다.
- 온라인이라는 글자가 붙는 이유는 데이터 조작에 HTTP/HTTPS를 통한 API가 사용되기 때문.
- 또한 편리한 UI 인터페이스를 통해 어디서나 쉽게 데이터를 저장하고 불러올 수 있어 개발자가 쉽게 웹 규모 컴퓨팅 작업을 수행할 수 있도록 함.
- S3는 객체 스토리지(객체로 된 파일을 다루는 저장소)이기 때문에 S3에 파일을 설치하는 행위는 할 수 없고, 이미지나 동영상 파일 등만을 저장할 수 있음.
- 즉, 파일 업로드, 삭제, 업데이트만 가능하지, 프로그램을 설치해서 저장하는 기능은 없다고 보면 된다.
S3를 사용하는 이유
- S3는 저장 용량이 무한대이고 파일 저장에 최적화되어 있어, 용량을 추가하거나 성능을 높이는 작업이 필요 없다.
- 비용은 EC2와 EBS로 구축하는 것보다 훨씬 저렴함.
- S3 자체가 수천 대 이상의 매우 성능이 좋은 웹 서버로 구성되어 있어서 EC2와 EBS로 구축했을 때 처럼 Auto Scaling이나 Load Balancing에 신경쓰지 않아도 된다.
- 웹하드 서비스와 비슷하지만, 별도의 클라이언트 설치나 ActiveX를 통하지 않고, HTTP 프로토콜(restful)로 파일 업로드/다운로드 처리가 가능.
- S3 자체로 정적 웹서비스가 가능.
- 동적 웹페이지와 정적 웹페이지가 섞여있을 때 동적 웹페이지만 EC2에서 서비스하고 정적 웹페이지는 S3를 이용하면 성능도 높이고 비용도 절감할 수 있다.
S3 사용 예
- 클라우드 저장소 (개인 파일 보관, 구글 드라이브처럼 사용 가능)
- 서비스의 대용량 파일 저장소 - 이미지, 동영상, 빅데이터 (ex: 넷플릭스)
- 서비스 로그 저장 및 분석
- AWS 아데나를 이용한 빅데이터 업로드 및 분석
- 서비스 사용자의 데이터 업로드 서버 (이미지 서버, 동영상 서버)
- 중요한 파일은 EC2의 SSD (EBS: Elastic Block Store)에 저장하지 말고 S3에 저장
- glacier와의 연동으로 비용 절감 및 규정 준수 가능 (빙하라는 뜻으로 자주 쓰지 않는 데이터를 S3에서 자동으로 변환)
결론
- S3의 주요 특징:
- 무제한에 가까운 저장 용량과 안정적인 성능을 제공
- 파일 저장에 최적화된 객체 스토리지로, EC2와 EBS 대비 저렴한 비용
- 정적 웹 콘텐츠를 S3에 호스팅하여 성능 향상 및 비용 절감
- 도입 이유:
- 대규모 트래픽과 데이터 증가에 유연하게 대응
- 데이터 저장 및 전송을 간소화하여 인프라 관리 부담 감소
- 케이타운포유는 Amazon S3를 도입해 이미지 콘텐츠 및 대용량 로그를 효율적으로 저장하고 분석함.
- 결과적으로, S3 도입으로 케이타운포유는 대용량 데이터 관리와 비용 최적화를 실현하며, 서비스 안정성을 높임.
Amazon Aurora
Amazon Aurora란?
- MySQL 및 PostgreSQL과 호환되는 완전 관리형 관계형 데이터베이스 엔진
- 특징:
- 고성능 스토리지와 고속 처리 능력: Aurora는 MySQL의 성능을 최대 5배, PostgreSQL의 성능을 최대 3배까지 높일 수 있다.
- 스토리지가 자동으로 조정되어 최대 128TiB(테비바이트)까지 확장 가능하다.
- 기존 MySQL, PostgreSQL 애플리케이션을 거의 변경하지 않고도 성능을 향상시킬 수 있다.
- 데이터베이스의 클러스터링과 복제를 자동으로 처리해 복잡한 관리 작업을 줄인다.
- 추가 참고 자료
- PostgreSQL: 고급 기능을 제공하는 오픈 소스 RDBMS. 데이터 무결성, ACID 준수에 강점.
- Aurora Serverless v2: 클러스터의 용량을 자동으로 조정하여 운영 중단 없이 CPU 및 메모리를 동적으로 확장하는 기능
- Route 53: DNS 웹 서비스로, 트래픽을 효율적으로 라우팅
케이타운포유의 Amazon Aurora Auto Scaling 개선 사례
- 비즈니스 환경:
- 케이타운포유는 이벤트 발생 시 평소보다 수십 배 이상의 트래픽 증가를 겪습니다.
- 기존 아키텍처 문제:
- 실시간 데이터베이스 부하: 캐시를 활용하더라도 API 호출이 많은 실시간 쿼리로 인해 DB 부하 발생
- 오토스케일링 한계:
- Scale-out 시, 평균 15분 소요
- 이벤트 발생 전, 수 시간 전에 읽기 전용 인스턴스를 미리 증설해야 하는 부담
- 예측 불가능한 이벤트로 인해 과도한 리소스 사용 및 비용 낭비
개선 목표 및 아이디어
- 핵심 요구사항:
- 순간적인 트래픽 스파이크 대응
- 비용 최적화
- 기존 Aurora 오토스케일링의 시간 지연 문제 해결
- 개선 아이디어:
- Serverless v2 인스턴스 활용: 기존 프로비저닝된 클러스터에 추가해 하이브리드 구조를 구성
- 고해상도 메트릭 기반의 감지: 1초 단위의 메트릭을 수집하여 스파이크 상황을 빠르게 감지
- 가중치 기반 트래픽 분배: 임계치 초과 시 트래픽을 Serverless 인스턴스로 자동 분배
개선된 오토스케일링 아키텍처
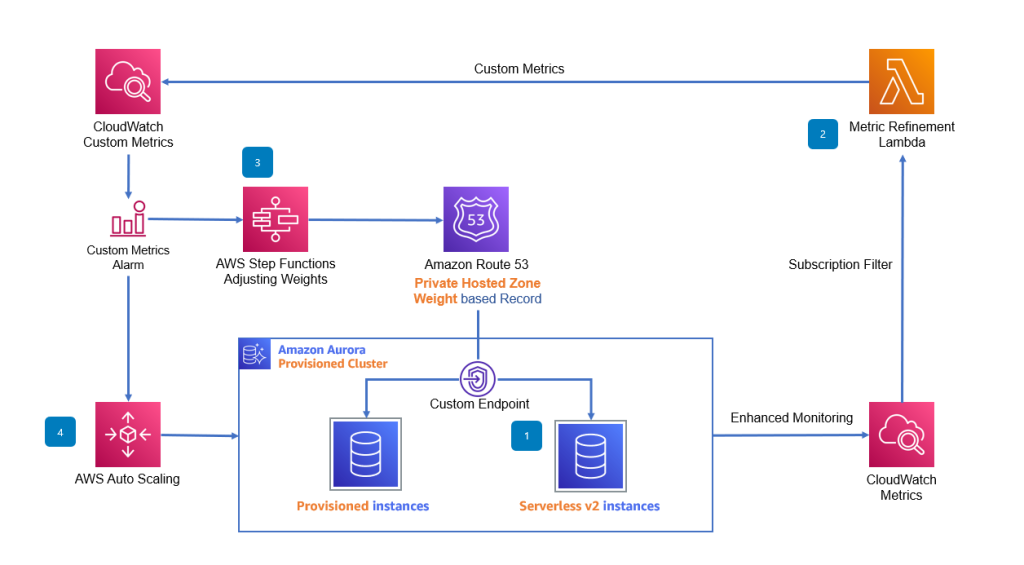
- Aurora Mixed-Configuration Cluster 구성:
- 프로비저닝된 인스턴스: 기본 트래픽 처리 담당
- Serverless v2 인스턴스: 스파이크 트래픽 대응을 위해 임계치 초과 시 트래픽 분산
- 가중치 조절: 트래픽 부하에 따라 가중치를 조정해 자동으로 트래픽 분배
- 자동화된 트래픽 조절 작동 원리:
- 평상시 Serverless v2 인스턴스의 가중치는 0
- CPU 임계치 초과 시, 알람이 발생하며 가중치 증가
- 프로비저닝된 인스턴스 추가 후, 트래픽 재분배 및 Serverless 인스턴스 사용 중지
아키텍처 주요 요소
- Aurora Serverless v2 읽기 전용 인스턴스 추가 및 커스텀 엔드포인트 설정:
- Serverless v2 인스턴스를 클러스터에 추가하여 가중치 0으로 설정
- 각 엔드포인트를 Route53에 연결하여 가중치 기반 라우팅을 설정
- Enhanced Monitoring & 고해상도 메트릭 수집:
- 기본 메트릭(60초 주기)보다 더 높은 해상도를 위해 Enhanced Monitoring 활성화
- 1초 단위의 RDSOSMetrics를 CloudWatch에 수집 및 커스텀 메트릭 생성
- Step Functions를 이용한 자동 트래픽 조절:
- 알람 발생 시, Step Functions이 자동으로 트래픽 비율을 조절
- 지속적인 모니터링을 통해 트래픽 변동 상황에 맞춰 실시간 조정
- 커스텀 메트릭 기반 오토스케일링:
- 평균 CPU 사용량 기준으로 오토스케일링을 설정하되, Serverless 인스턴스를 포함하지 않음
- 커스텀 메트릭을 기반으로 TargetTrackingScaling 정책 구성
테스트 결과
AS-IS : Aurora Cluster (Provisioned Only)
트래픽 스파이크로 인해 약 15분간 CPU 100% 도달 및 서비스 장애 발생
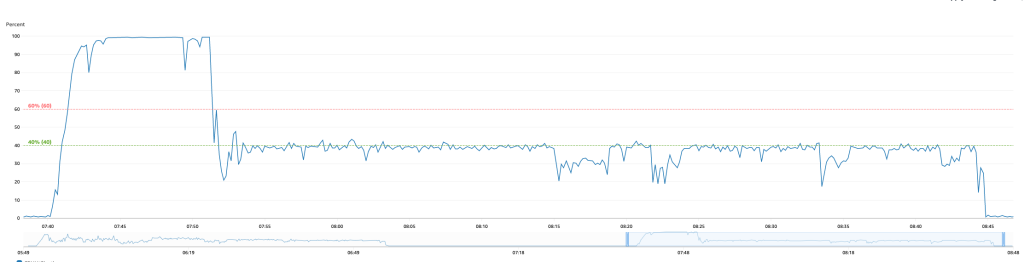
평균 CPU 사용률
TO-BE : Aurora Hybrid Cluster (Provisioned + Serverless v2)
Serverless v2를 통해 순간적인 CPU 부하 해소, 안정적인 성능 유지
프로비저닝 인스턴스 추가 후 Serverless 트래픽 비율 감소
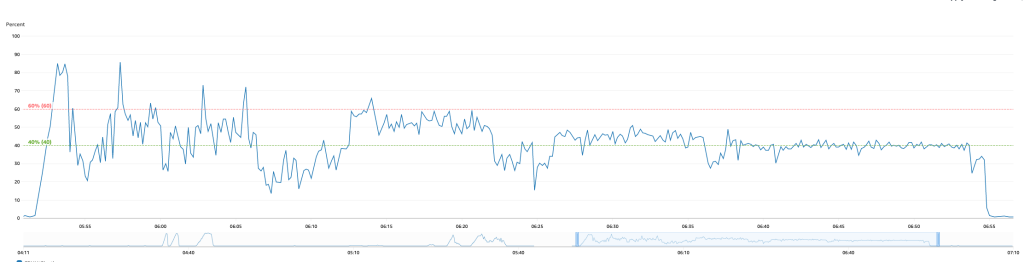
평균 CPU 사용률
성과 및 효과
- 서비스 안정성: 예측 불가능한 글로벌 스파이크 트래픽에 안전하게 대응
- 시스템 성능 향상: 초기 부하 상태에서 응답 속도 220ms → 80ms로 개선
- 오토스케일링 시간 단축: 메트릭 주기 60초 → 10초
- 비용 절감: 불필요한 사전 증설 제거로, 이벤트 대응 비용 약 30% 절감
결론 및 추천
- Aurora Hybrid Cluster 활용: 예측 불가한 트래픽 상황에 최적화된 아키텍처
- 운영 및 관리 부담 감소: 자동화된 모니터링 및 오토스케일링
- 향후 확장 가능성: Serverless v2 인스턴스를 활용해 다양한 데이터베이스 요구사항에 대응
마무리
- Aurora Serverless v2 및 Mixed-Configuration Cluster는 효율적인 오토스케일링 전략으로 안정적인 서비스 제공을 위한 핵심 아키텍처가 될 것
- 적용 대상:
- 비즈니스 이벤트 시 높은 트래픽을 경험하는 기업
- 빠르고 유연한 오토스케일링이 필요한 환경
멀티 AZ 환경과 ELB
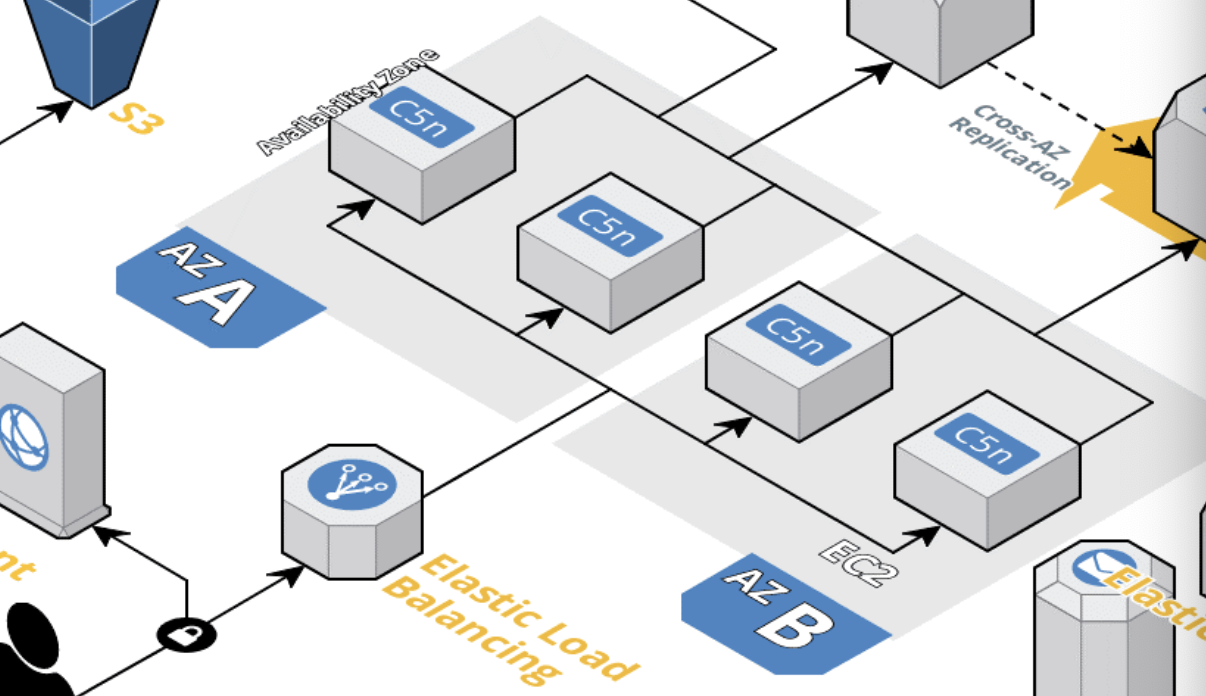
KTOWN4U의 ELB 도입 이유
ELB을 활용해 부하 분산 및 유동성을 확보
구조
두 개의 가용 영역(AZ A와 AZ B)에 각각 두 개의 EC2 인스턴스(C5n)가 배치되어 있고, 이 인스턴스들을 하나의 ELB(Elastic Load Balancing)가 관리하고 있는 구조
AZ 도입 이점
우선 리전이란 개념을 알아야 하는데, 리전은 인프라를 지리적으로 나누어 배포한 것을 의미한다. 사용자와 리전을 가깝게 해야 network latency를 최소화할 수 있다.
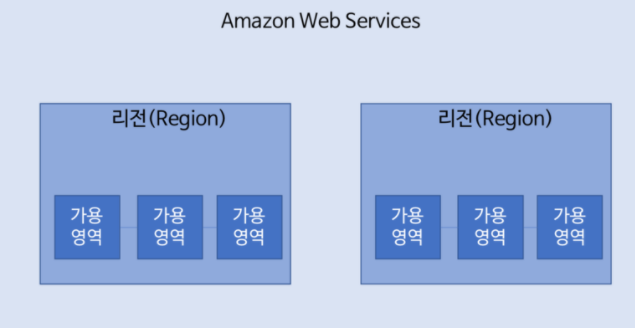
이 리전에서 개별의 데이터센터로 분리해놓은 것을 가용 영역(Availability Zone)이라 한다. 왜 AZ를 여러 개를 둘까? 이는 자연재해 및 정전 등의 재해로부터 자유로워지기 위해서이다. HA(고가용성) 을 위해 리전 내 복수의 가용 영역에 데이터(RDS)와 애플리케이션(EC2)를 배포하는 것이 좋다. 이를 통해 한 AZ의 서버가 죽어도 다른 AZ로 안정적으로 서비스 운영을 유지할 수 있다.
Elastic IP (탄력적 IP) AWS에서 제공하는 Static IP Address 이다. 인스턴스 장애가 발생한 AZ로부터 다른 AZ로 인스턴스 주소를 신속히 변경할 수 있다.
ELB 도입 이점
- 부하 분산
ELB는 네트워크 트래픽을 여러 대상으로 균등하게 분배하여 특정 서버에 과도한 부하가 걸리지 않도록 한다.AWS: Application Load Balancing, Network Load Balancing 및 Gateway Load Balancing의 차이점은 무엇인가요?
ALB는 들어오는 트래픽을 EC2 인스턴스를 비롯한 여러 대상에 분산합니다.
- 서비스 중단 최소화 (고가용성 확보)
한 가용 영역에서 문제가 발생할 경우, 다른 가용 영역에서 서비스가 지속적으로 제공된다.
AWS: Regions and Availability Zones
가용 영역은 다른 모든 가용 영역과 수 킬로미터에 상당하는 유의미한 거리를 두고 물리적으로 분리되어 있다. (다만 모든 가용 영역은 서로 100km(60마일) 이내의 거리에 위치한다.)
- 엔드포인트 역할 제공
- 트래픽을 하나의 경로로 받아서 다수의 인스턴스에 분산한다. 유저 입장에서는 각각의 인스턴스에 일일히 접근해서 관리하는 게 아닌 하나의 주소로 접속해서 관리할 수 있게 된다.
Elastic Load Balancing
AWS: Application Load Balancing, Network Load Balancing 및 Gateway Load Balancing의 차이점은 무엇인가요?
Application Load Balancer
로드 밸런싱의 주요 목적은 서버 부하 분산이다. 트래픽이 몰릴 때 특정 서버로 부하가 몰리지 않도록 적절히 분산해주는 역할을 한다. 이는 EC2뿐만 아니라 ECS의 컨테이너, Lambda 등에도 해당된다. 네트워크에서는 이를 L4/L7 Switch(OSI 4계층) 이라 부르며 클라우드 환경에서는 로드 밸런서라고 부른다.
- L4 Switch
4계층(Transport) IP/Port level에서 로드밸런싱 한다. 즉, 서버 A와 서버 B로 부하를 분산한다.
- L7 Switch
7계층(Application) User Request level에서 로드밸런싱 한다. 즉, /category 와 /search를 담당 서버들로 로드밸런싱
또 ELB는 트래픽을 분산함으로써 특정 인스턴스나 AZ에 장애가 발생해도 자동으로 다른 인스턴스로 트래픽을 리다이렉트하여 서비스의 무중단 운영을 가능하게 한다.
ELB는 Auto Scaling과 함께 사용된다. 이때 자동으로 늘어난 인스턴스는 로드밸런서에 자동으로 등록되며, 마찬가지로 종료된 인스턴스도 로드밸런서에서 자동으로 등록 취소된다. 인스턴스가 증가하더라도 LB 는 하나의 엔드포인트가 제공하기 때문에 사용자는 다른 인스턴스에 접속하더라도 같은 엔드포인트로 접속하면 된다.
다음은 다양한 유형의 LB이다.
Application Load Balancer
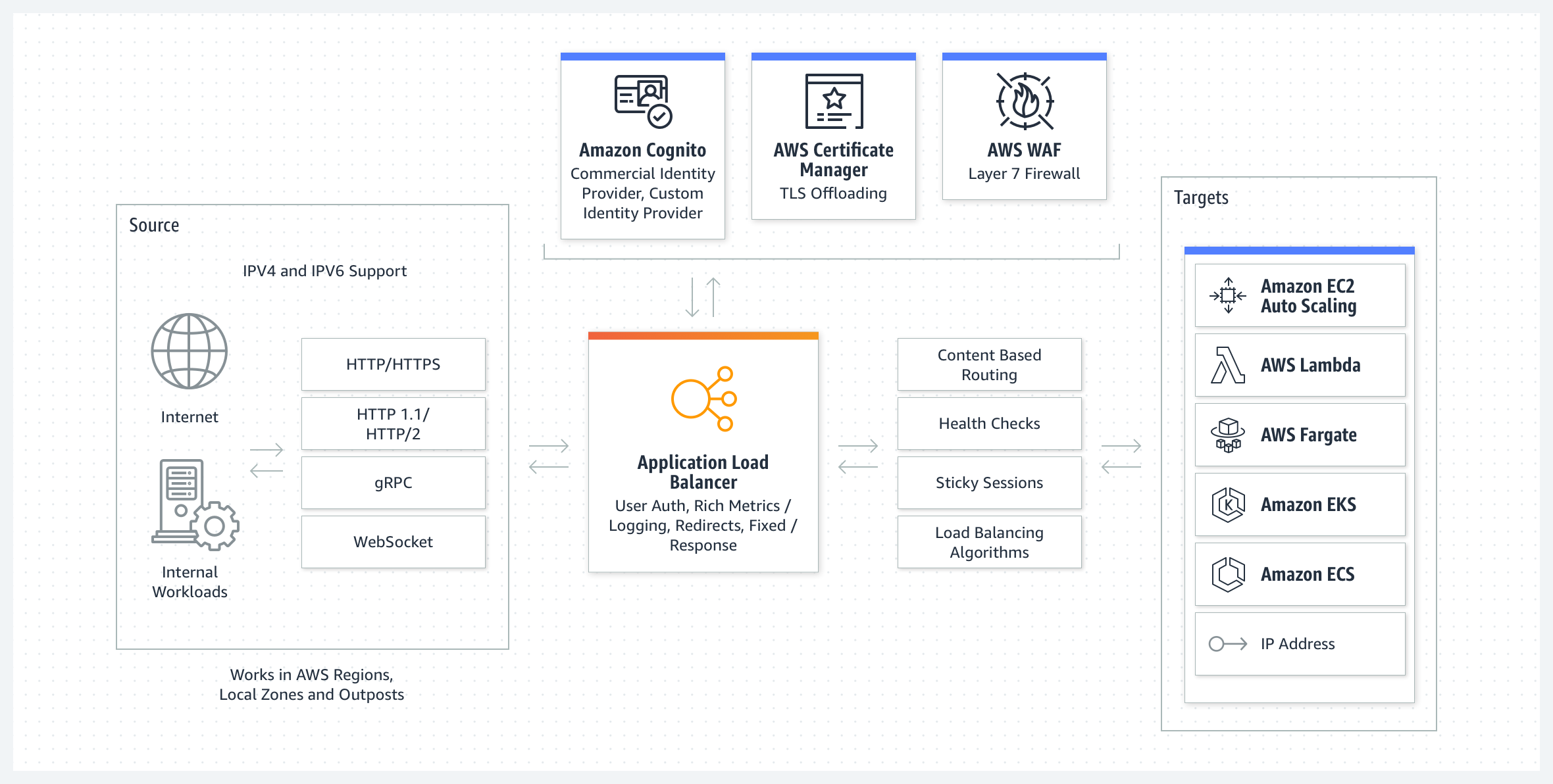
ALB는 들어오는 트래픽을 EC2 인스턴스를 비롯한 여러 대상에 분산한다. 유연한 애플리케이션 수준의 트래픽 관리 및 라우팅이 필요한 경우에 적합하다. 마이크로서비스, 컨테이너화된 환경, 웹 애플리케이션에 가장 적합하다.
예시
전자 상거래 애플리케이션에는 제품 디렉터리, 장바구니 및 결제 기능이 있다. ALB는 이미지와 비디오를 포함하지만 열린 연결을 유지할 필요가 없는 서버에 제품 검색 요청을 전송한다. 이에 비해 클라이언트 연결을 유지하고 장바구니 데이터를 오랫동안 저장하는 서버로 장바구니 요청을 전송한다.
Gateway Load Balancer
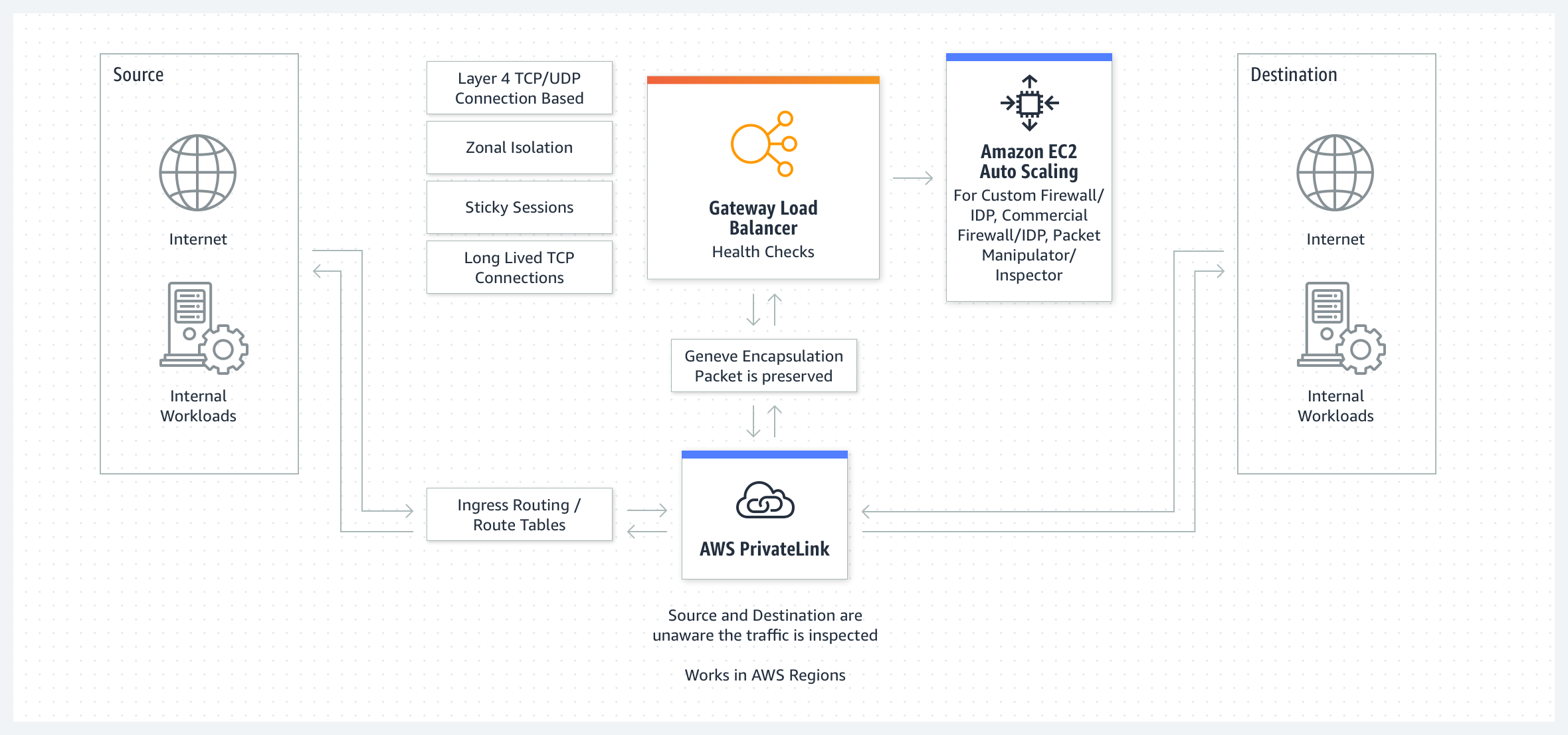
GLB를 사용하여 침입 탐지 및 방지, 방화벽 심층 패킷 검사 시스템과 같은 가상 어플라이언스를 배포, 관리 및 확장할 수 있다.
Network Load Balancer
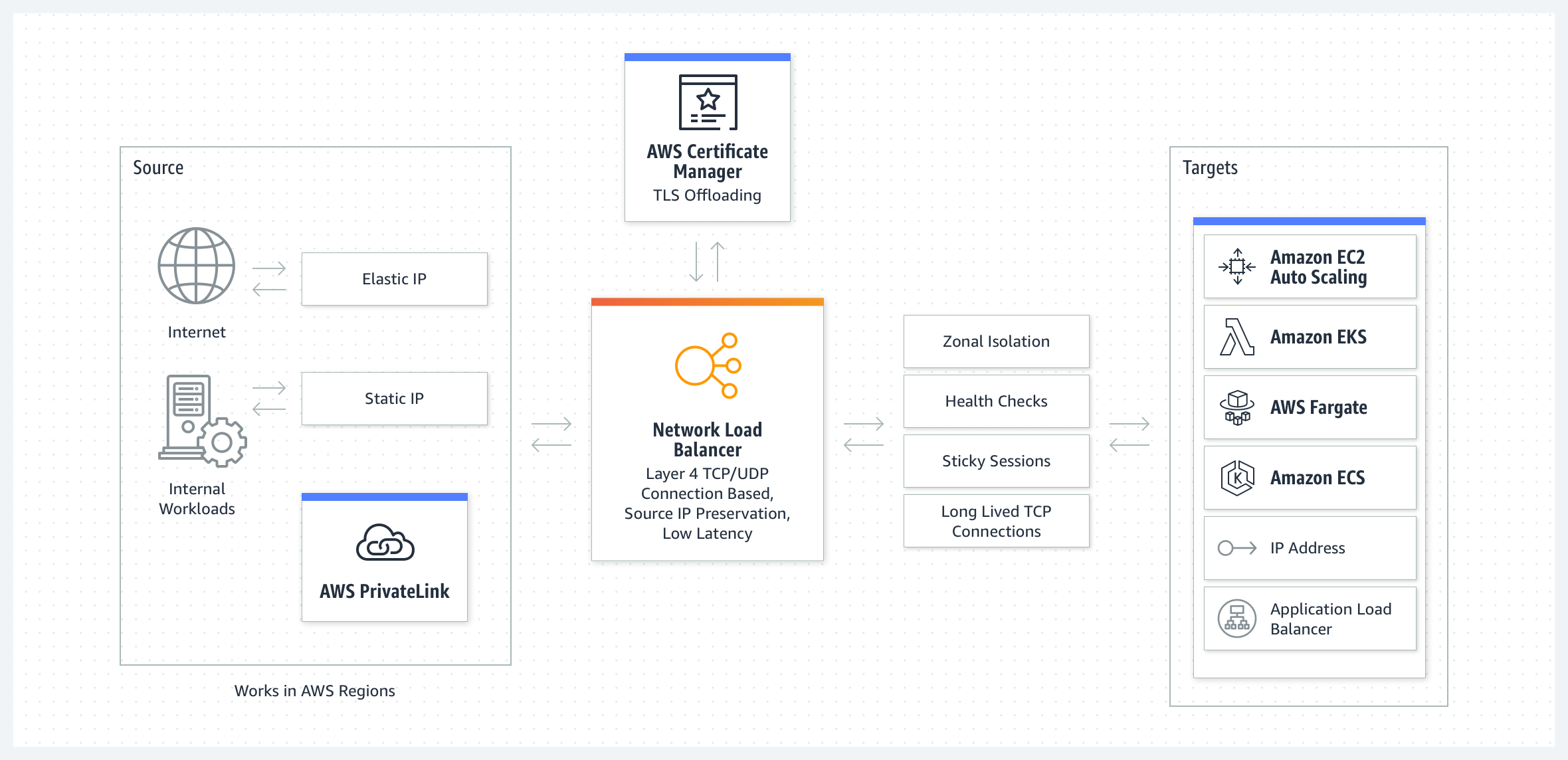
NLB는 네트워크 상태에 따라 트래픽을 분산한다.
예시
중복된 데이터가 포함된 데이터베이스 서버가 여러 개 있는 경우, NLB는 미리 정해진 서버 IP 주소 또는 서버 가용성에 따라 트래픽을 라우팅한다.
비교
| ALB | NLB | GLB | |
|---|---|---|---|
| OSI 계층 | 계층 7 | 계층 4 | 계층 3 및 계층 7 |
| 대상 유형 (트래픽을 라우팅하는 엔드 포인트) | IP, 인스턴스 및 Lambda 대상 유형 | IP, 인스턴스 및 ALB 대상 유형 | IP 및 인스턴스 대상 유형 |
| 프록시 동작 | 연결 종료 | 연결 종료 | 흐름을 종료하지 않음 |
| 프로토콜 | HTTP, HTTPS 및 gRPC 프로토콜 | TCP, UDP 및 TLS 프로토콜 지원 | IP 기반 라우팅 지원 |
| 알고리즘 | 라운드 로빈 | 플로우 해시 | 라우팅 테이블 조회 |
Amazon EC2
Amazon EC2 인스턴스 네이밍
| 인스턴스 패밀리 | 세대 | 추가 기능 | 구분자 | 인스턴스 크기 | |
|---|---|---|---|---|---|
| 예시 | c | 5 | n | . | large |
Amazon EC2 인스턴스 패밀리
범용 인스턴스
- 용도 균형 있는 컴퓨팅, 메모리 및 네트워킹 리소스를 제공하며, 다양한 여러 워크로드에 사용할 수 있다. 이 인스턴스는 웹 서버 및 코드 리포지토리와 같이 이러한 리소스를 동등한 비율로 사용하는 애플리케이션에 적합하다.
- 인스턴스

유형 | 유형명 | 의미 | | — | — | | Mac | macOS | | M | 범용 (vCPU 1개, 4GB 메모리) | | T | 버스트가 가능한 CPU | | A | ARM 기반 |
컴퓨팅 최적화 인스턴스
- 용도 고성능 프로세서를 활용하는 컴퓨팅 집약적인 애플리케이션에 적합하다. 이 범주에 속하는 인스턴스는 배치처리 워크로드, 미디어 트랜스코딩, 고성능 웹 서버, 고성능 컴퓨팅(HPC), 과학적 모델링, 전용 게임 서버 및 광고 서버 엔진, 기계 학습 추론 및 기타 컴퓨팅 집약적인 애플리케이션에 매우 적합하다.
- 인스턴스

- 유형
유형명 의미 C 컴퓨팅 최적화
메모리 최적화 인스턴스
- 용도 메모리에서 대규모 데이터세트를 처리하는 워크로드를 위한 빠른 성능을 제공하기 위해 설계되었다.
- 인스턴스

- 유형
유형명 의미 R 초대형 메모리 X 랜덤 액세스 메모리(RAM) z 고주파수 메모리
가속 컴퓨팅 인스턴스
- 용도 하드웨어 엑셀러레이터 또는 코프로세서를 사용하여 부동 소수점 수 계산이나 그래픽 처리, 데이터 패턴 일치 등의 기능을 CPU에서 실행되는 소프트웨어보다 훨씬 효율적으로 수행한다.
- 인스턴스

- 유형
유형명 의미 P 프리미엄 GPU G GPU F FPGA (Field Programmable gate Array)
스토리지 최적화 인스턴스
- 용도 로컬 스토리지에서 매우 큰 데이터 세트에 대해 많은 순차적 읽기 및 쓰기 액세스를 요구하는 워크로드를 위해 설계되었다. 애플리케이션에 대해 대기 시간이 짧은, 수만 단위의 무작위 초당 I/O 작업 수(IOPS)를 지원하도록 최적화되었다.
- 인스턴스

- 유형
유형명 의미 D Dense Storage (고밀도 스토리지) H HDD I NVMe (Non-Volatile Memory Express)
추가 기능
| 추가 기능명 | 의미 |
|---|---|
| a | AMD 프로세서 |
| b | 블록 스토리지 최적화 |
| d | 인스턴스 스토어 볼륨 (휘발성) |
| e | 추가 스토리지 또는 메모리 |
| g | AWS Graviton 프로세서 |
| i | 인텔 프로세서 |
| n | 네트워크 최적화 |
| z | 고주파 |
C5n EC2 인스턴스 종류
AWS: 신규 C5n EC2 인스턴스 타입 출시 – 100Gbps 네트웍 대역폭 지원
최대 100Gbps의 네트워크 대역폭을 통해 시뮬레이션, 인메모리 캐시, 데이터 레이크 및 기타 대규모의 통신처리를 필요로하는 애플리케이션들이 이전보다 훨씬 원활하게 실행됩니다.
인스턴스 이름 vCPUs RAM EBS 대역폭 네트워크 대역폭 c5n.large 2 5.2GiB Up to 3.5Gbps Up to 25Gbps c5n.xlarge 4 10.5GiB Up to 3.5Gbps Up to 25Gbps c5n.2xlarge 8 21GiB Up to 3.5Gbps Up to 25Gbps c5n.4xlarge 16 42GiB 3.5Gbps Up to 25Gbps c5n.9xlarge 36 96GiB 7Gbps 50Gbps c5n.18xlarge 72 192GiB 14Gbps 100Gbps
인스턴스 구입 옵션
온디맨드 인스턴스
- 시작하는 인스턴스에 대한 비용을 초 단위로 지불
절감형 플랜(Savings Plans)
- 1년 또는 3년 기간 동안 시간당 USD로 일관된 사용량을 약정하여 비용 절감
예약 인스턴스
- 1년 또는 3년 기간 동안 인스턴스 유형 및 리전을 포함하여 일관된 인스턴스 구성을 약정
스팟 인스턴스
- 미사용 EC2 인스턴스를 요청하여 EC2 비용을 대폭 줄임
전용 호스트
- 인스턴스 실행을 전담하는 실제 호스트 비용을 지불하며, 기존의 소켓, 코어 또는 VM 소프트웨어별 라이선스를 가져와 비용 절감
전용 인스턴스
- 단일 테넌트 하드웨어에서 실행되는 인스턴스 비용을 시간 단위로 지불
용량 예약
- 특정 가용 영역의 EC2 인스턴스에 대해 용량 예약
Amazon ElastiCache
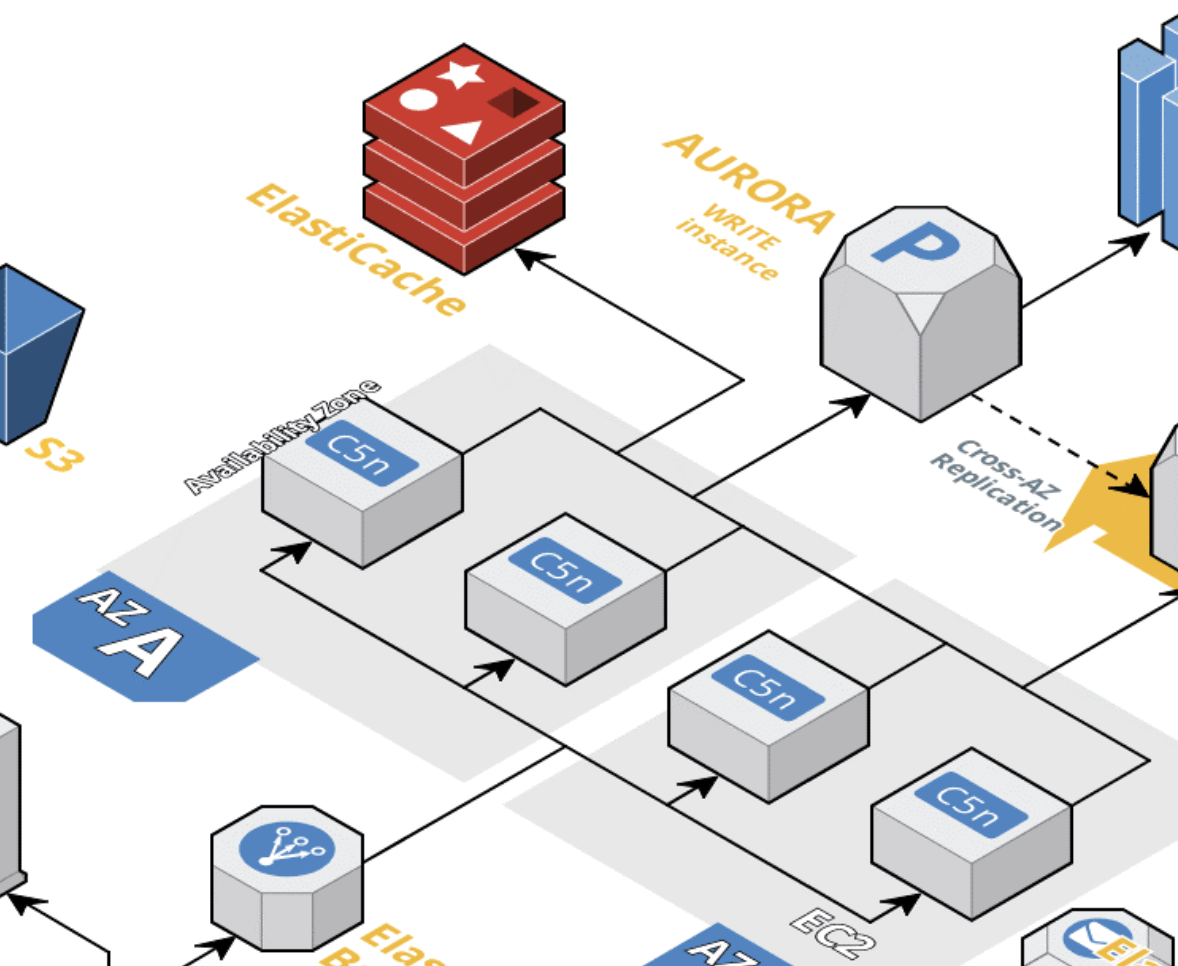
KTOWN4U의 ElastiCache 도입 이유
ElastiCache를 활용한 캐시를 도입하여 데이터베이스에 직접적인 부하를 감소시킬 수 있도록 구성했습니다.
구조
EC2 인스턴스와 ElastiCache가 연결되어 있고, Aurora 데이터베이스와는 연결되지 않은 구조
ElastiCache 도입 이점 및 사용 사례
- Amazon ElastiCache
- 이점
- 빠른 응답 시간
- 비용 최적화된 성능
- 용량 관리 불필요
- 비즈니스 지속성 유지
- Redis OSS 및 Memcached 호환 가능
- 사용 사례
- 백엔드 데이터베이스 로드를 줄여 총 소유 비용 절감
- 데이터를 캐시하고 데이터베이스 I/O를 오프로드하여 운영 부담을 줄이고 비용을 절감하여 데이터베이스 및 애플리케이션 성능을 개선
- 실시간 애플리케이션 데이터 캐싱
- 실시간 세션 스토어
- 실시간 순위표
- 이점
엔진 비교
| 특징 | Redis OSS | Memcached |
|---|---|---|
| 데이터 구조 | 문자열, 리스트, 셋, 해시, 정렬된 셋 등 다양한 데이터 구조 지원. | 단순한 키-값 저장만 지원. (문자열) |
| 영속성 | 디스크에 데이터를 저장하여 영속성 제공. | 영속성 없음 (메모리에만 데이터 저장) |
| 복제 및 페일오버 | 기본적으로 지원 (마스터-슬레이브 복제 및 자동 페일오버 가능) | 지원하지 않음 |
| 스크립팅 | Lua 스크립팅 지원 | 스크립팅 지원 없음 |
| 클러스터링 | Redis 클러스터 기능으로 수평적 확장 가능 | 클러스터링 기본적으로 지원하지 않음 |
| 트랜잭션 | MULTI/EXEC 명령어를 통해 트랜잭션 지원 | 트랜잭션 지원 없음 |
| 메모리 관리 | LRU(Least Recently Used) 외 다양한 정책 지원 | LRU(Least Recently Used) 정책만 지원 |
| 사용 사례 | 세션 관리, 채팅 애플리케이션, 실시간 분석 등 복잡한 데이터 구조가 필요한 경우 | 단순한 캐싱, 데이터베이스 쿼리 결과 캐싱 등 단순 캐싱 목적 |
| 성능 | 다양한 기능과 구조로 인해 성능이 약간 낮을 수 있음 | 단순 구조로 인해 매우 빠름 |
| 백업 및 복구 | 스냅샷을 이용해 백업 및 복구 가능 | 백업 및 복구 기능 없음 |
캐싱 전략
지연 로딩 (Lazy loading)
전략 필요할 때에만 데이터를 캐시에 로드하는 전략 장점 - 요청된 데이터만 캐싱됨
- 노드 장애가 애플리케이션에 치명적인 영향을 주지 않음(노드 장애 : 서버나 네트워크 구성 요소 중 하나가 정상적으로 작동하지 않거나 완전히 멈추는 상황)단점 - 캐시 누락 패널티(캐시에 요청된 데이터가 존재하지 않을 때 발생하는 성능 저하)
1. 캐시에서 데이터에 대한 초기 요청
2. 데이터에 대한 데이터베이스의 쿼리
3. 캐시에 데이터 작성
- 캐시에 저장된 데이터가 시간이 지남에 따라 오래되거나 최신 상태가 아닐 수 있음라이트-스루 (Write-through)
전략 데이터베이스에 데이터를 작성할 때마다 데이터를 추가하거나 캐시의 데이터를 업데이트하는 전략 장점 - 캐시에 저장된 데이터가 항상 최신 상태
- 쓰기 패널티 > 읽기 패널티 (사용자는 일반적으로 데이터를 업데이트할 때 지연시간에 더 관대)단점 - 누락된 데이터 (ex. 캐시가 처음 시작할 때 비어있고, 특정 데이터에 대한 요청이 아직 발생하지 않은 경우)
- 캐시 이탈 (캐시가 가득 찼을 때 덜 중요한 데이터가 제거되어 새로운 데이터를 저장할 공간을 확보하는 과정. 캐시 이탈이 발생하면, 자주 사용되거나 중요한 데이터가 캐시에서 제거될 수 있음)추가 전략 - TTL 추가 (Adding TTL): 캐시에서 유효 기간을 설정하여 데이터가 오래되거나 불필요하게 남아 있지 않도록 관리하는 전략
추천시스템 로직
Amazon Aurora에 적재된 데이터를 DMS를 활용해 Amazon Redshift로 동기화하고, 데이터를 **Amazon Managed Workflows for Apache Airflow(MWAA)**와 ETL 서비스를 사용해 추출이 용이한 형태로 변환 후 Elasticsearch와 Amazon Personalize와 연동해 데이터를 분석하고 개인화 영역에서 활용할 수 있도록 구축했습니다.
- 케이타운포유 아키텍처에서 추천 시스템에 대해 생략된 부분이 매우 많음
→ 모든 서비스는 AWS의 서비스를 이용했다고 가정 후 진행
RedShift
클라우드에서 완전히 관리되는 페타바이트급 데이터 웨어하우스 서비스
데이터 웨어하우스(DW)란?
- 데이터 웨어하우스는 비즈니스 인텔리전스(BI) 활동을 지원하는 데이터 관리 시스템
- 비즈니스 인텔리전스(BI)란, 데이터를 수집, 정리, 분석하고 활용하여 더 나은 의사 결정을 내릴 수 있도록 지원하는 기술
- 여러 소스로부터 얻은 데이터를 중앙 집중화 및 통합하는 중앙 리포지토리
- 쿼리 및 분석 수행
RedShift 특징
클러스터 구조로, 리더 노드와 컴퓨팅 노드를 가짐
노드 기능 리더 노드 • 외부 통신 처리
• 쿼리 실행계획 작성컴퓨팅 노드 • 컴파일된 코드 실행(쿼리 수행)
• 실행 후 결과를 리더 노드에게 전송열 기반 데이터 스토리지
- 데이터베이스 테이블 정보를 열 기반 방식으로 저장
- 디스크 입출력 호출 및 로드해야 하는 데이터 크기가 감소하는 이점을 가짐
- 열 기반 방식 덕분에 쿼리 성능, 데이터 처리 속도가 빨라짐
대용량 병렬 처리를 통해 복잡한 쿼리도 빠른 속도로 실행
케이타운포유: 아키텍처에서 RedShift를 쓴 이유?
데이터 분석, 처리 서비스로는 Redshift 외에도 Athena, EMR이 존재
Athena Redshift EMR 정의 쿼리 서비스 데이터 웨어하우스 빅데이터 플랫폼 서버 서버리스 서버 클러스터 서버 클러스터 데이터 위치 S3 클러스터 내 로컬 저장소, S3 및 외부 데이터 소스 S3 외에 위치 가능 쿼리 대화형 쿼리 복잡한 쿼리에 빠른 성능 쿼리 실행 외에도 분산 처리, 분석 작업 Athena를 사용하지 않은 이유
케이타운포유 아키텍처는 Aurora에 저장된 데이터를 분석에 사용하기 때문
Athena는 S3에 저장된 데이터를 쿼리하는 서비스
RedShift는 S3, RDS 등 다양한 위치의 데이터를 분석 가능
→ Aurora에 저장된 데이터를 분석하는 것에는 RedShift가 적절하다.
단순 쿼리 서비스가 필요한 것이 아님
데이터를 BI, 개인화에 사용할 목적
단순 쿼리 서비스를 넘어서 대규모 데이터 세트를 처리하고 복잡한 분석을 수행할 수 있는 데이터 웨어하우스의 필요성을 가짐
→ BI 및 개인화 목적에는 데이터 웨어하우스 솔루션인 RedShift가 적절하다.
EMR을 사용하지 않은 이유
- 데이터 웨어하우스의 필요성
EMR은 빅데이터 처리와 데이터 정제 작업에 최적화된 서비스
케이타운포유가 필요로 하는 요소는 마케팅 및 비즈니스 인사이트이며 이는 빅데이터 처리에 중점을 두는 EMR보다 데이터 웨어하우스인 redshift에서 적절하게 제공 가능
→ BI에 초점을 두는 데이터 웨어하우스인 RedShift가 더 적절하다.
- 데이터 웨어하우스의 필요성
DMS
데이터를 쉽고 안전하게 이동할 수 있도록 지원하는 데이터베이스 마이그레이션 서비스
작동 방식
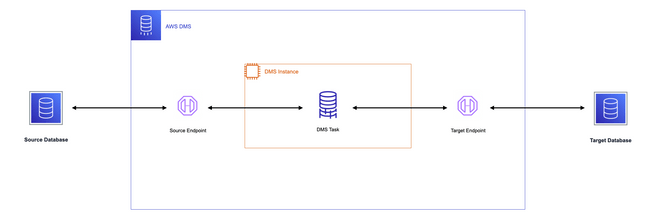
- Source, Target 엔드포인트, 데이터 복제 인스턴스 생성
- 복제 인스턴스를 통해 Replication Task 실행
- 데이터 복제 및 마이그레이션 진행
케이타운포유: DMS의 사용
- 케이타운포유 아키텍처는 DMS를 통해 Aurora에서 RedShift로 마이그레이션을 진행
ETL: Glue
서버리스 데이터 통합 서비스 · 완전 관리형 ETL 서비스
ETL이란?
- 추출, 전환, 적재(로드)
- 원시 데이터를 정리 및 구성해서 분석, 기계 학습 등의 용으로 준비하는 과정
- 소스 DB에서 관련 데이터 추출
- 분석에 적합한 형식으로 데이터 변환
- 데이터를 대상 DB에 로드
케이타운포유: ETL 서비스
- ETL 과정이 아키텍처에서 생략되어 있어 어떤 ETL 서비스를 사용했는지 확인이 불가능
- 추천 시스템에서 AWS Glue를 ETL 서비스로 사용했다고 가정
Glue 구성 요소
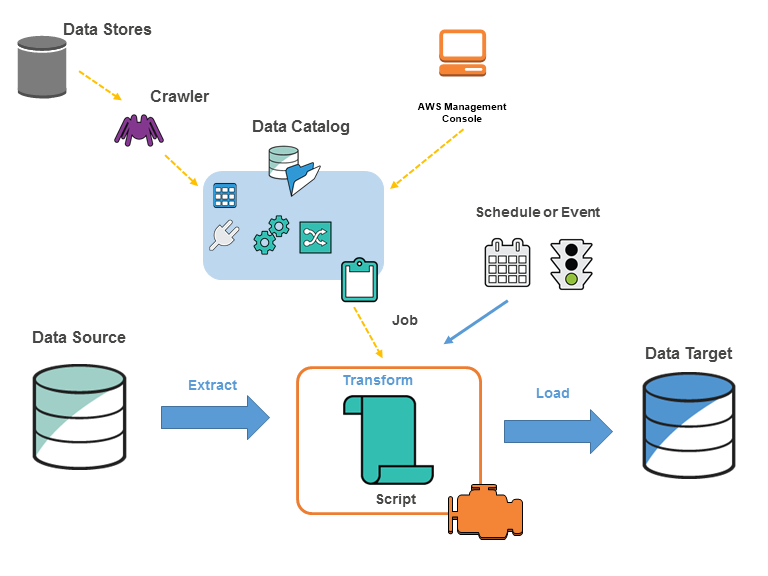
- Data catalog
- glue의 영구적 메타데이터 스토어
- Crawler
- 지정한 데이터 소스를 읽어 메타데이터를 추출해 data catalog에 테이블 생성
- Job
- ETL 작업을 수행하는데 필요한 비즈니스 로직
- Script
- ETL 작업 코드
Glue 과정
- 크롤러 정의
- 크롤러는 데이터 소스를 읽고 data catalog에서 메타데이터 테이블 생성
- Glue Job은 Data Catalog에 저장된 메타데이터를 참조하여 ETL 작업 정의
- 작업을 진행해 스크립트가 소스에서 데이터 추출, 변환 후 타켓으로 로드하는 ETL 과정 진행
Glue 사례: 올리브영 랭킹시스템
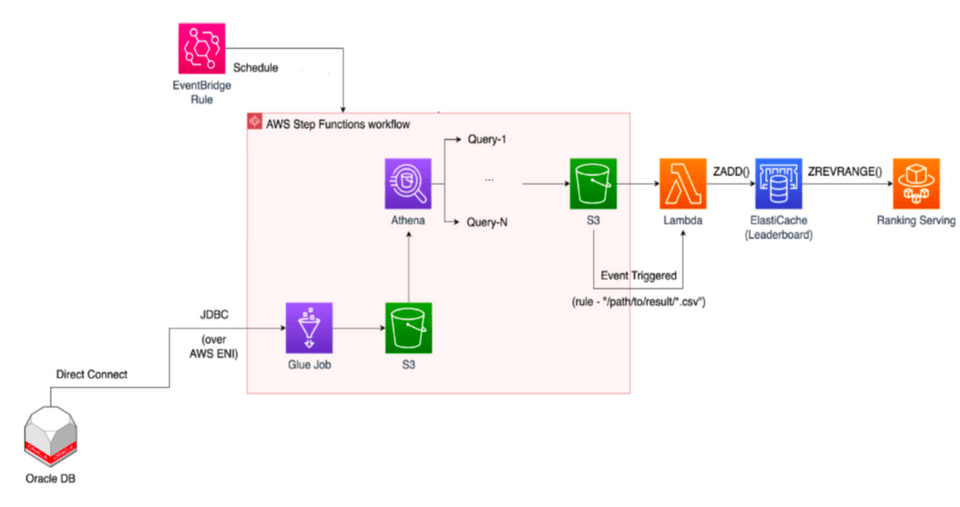
당면 과제
- 랭킹 서비스 개편을 통해 세분화된 판매 랭킹 카테고리를 제공해야 하는 상황에서 문제 발생
- 랭킹 세분화로 랭킹의 종류가 추가될수록 DB 자원의 비효율성이 증가
- 현재의 랭킹 산출 방식이 랭킹 데이터의 산출 근거 파악에 부적절
- 랭킹 서비스 개편을 통해 세분화된 판매 랭킹 카테고리를 제공해야 하는 상황에서 문제 발생
해결
- 기존의 산출방식 대신 신규 개발을 선택
- Glue + Athena + Step Function을 사용해 랭킹 산출 시스템을 구현
구현: Glue
- 데이터 카탈로그 생성을 위해 Glue 데이터베이스, 테이블 생성
- 크롤러 설정
- 기존의 RDB를 Glue Connector를 통해 연결
- ETL Job 생성, 이를 통해 ETL 진행
- Parquet 파일형식으로 전환하여 S3 버킷에 저장
→ 기존 RDB에서 랭킹 산출용 데이터의 ETL을 진행하고 Parquet 형식으로 전환해 S3 버킷에 저장
MWAA
Amazon Managed Workflows for Apache Airflow
Airflow란?
프로그래밍 방식으로 워크플로우를 작성, 예약 및 모니터링하는 오픈 소스 플랫폼
→ 워크플로우 관리 도구
Airflow 특징
- 파이썬을 이용한 데이터 파이프라인 정의
- 뛰어난 확장성
- 플러그인을 통한 쉬운 커스터마이징
- 편리한 웹 인터페이스
Airflow 기본 구성
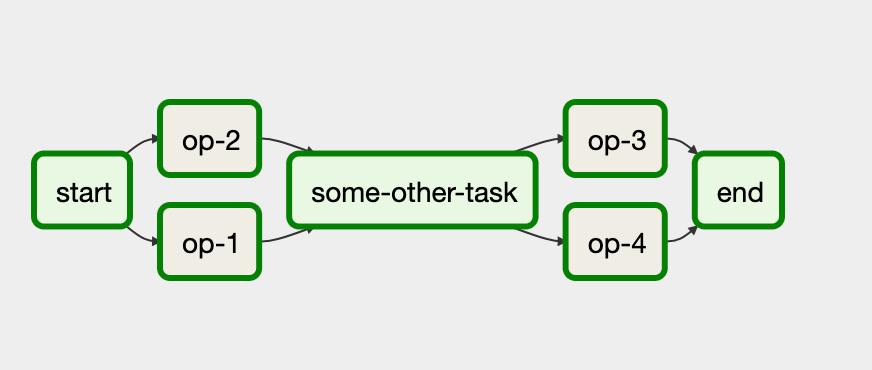
- DAG
- 반복 및 순환을 허용하지 않는 그래프
- Operator
- Task의 Wrapper 역할
- 실제 작업을 정의하는데 사용
- Action, Transfer, Sensor 타입이 존재
- Task
- DAG의 실행 단위
- Task 실행 시, Operator에서 정의한 작업을 수행
- Task Instance
- 개별 Task가 실행된 인스턴스
MWAA 정의
- Apache Airflow에 대한 관리형 오케스트레이션 서비스
- 데이터 파이프라인을 대규모로 설정하고 운영하는 데 사용
MWAA 작동 방식
- MWAA에 사용할 S3 버킷 지정
- S3에 DAG, 플러그인, Python 요구사항 저장
- 콘솔, CLI, SDK, Apache Airflow로 DAG 실행 및 모니터링
MWAA 사례: 29CM 개인화 추천시스템 기계학습운영(MLOps) 구축
Amazon SageMaker와 Amazon MWAA를 활용한 29CM의 개인화 추천시스템 MLOps 구축여정
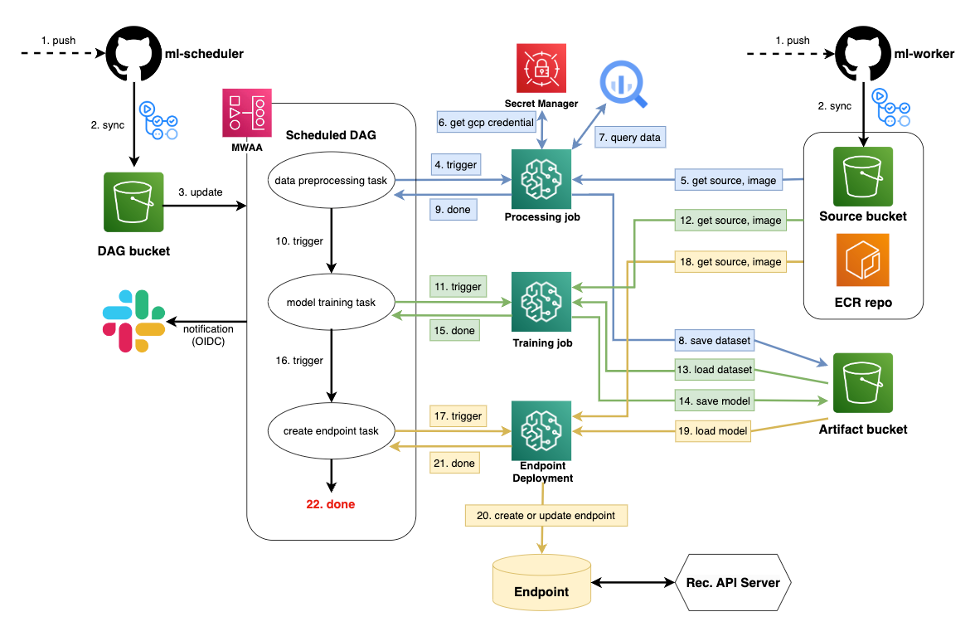
당면 과제
- 기존 카테고리 페이지는 모든 사용자가 동일한 순서로 정렬된 상품 목록이 제시
- 카테고리 페이지에서 노출되는 상품을 개인화 추천 기반으로 재정렬하는 시스템 도입
- 개인화 모델의 학습, 배포 과정을 자동화하기 위해 기계학습 운영(MLOps) 체계의 구축
구현
- SageMaker + MWAA를 통한 기계학습 운영 구축
- SageMaker의 데이터 전처리, 모델 학습, 모델 배포 과정을 각각 하나의 Task으로 정의
- DAG 형성
- DAG 파일, 플러그인, Python 요구사항을 S3(DAG bucket)에 저장
- MWAA가 자동으로 Airflow 환경 구축
→ MWAA를 통해 기계학습 운영(MLOps)을 구축, 전체 워크플로우를 자동화
MWAA + Glue 분석: 아키텍처
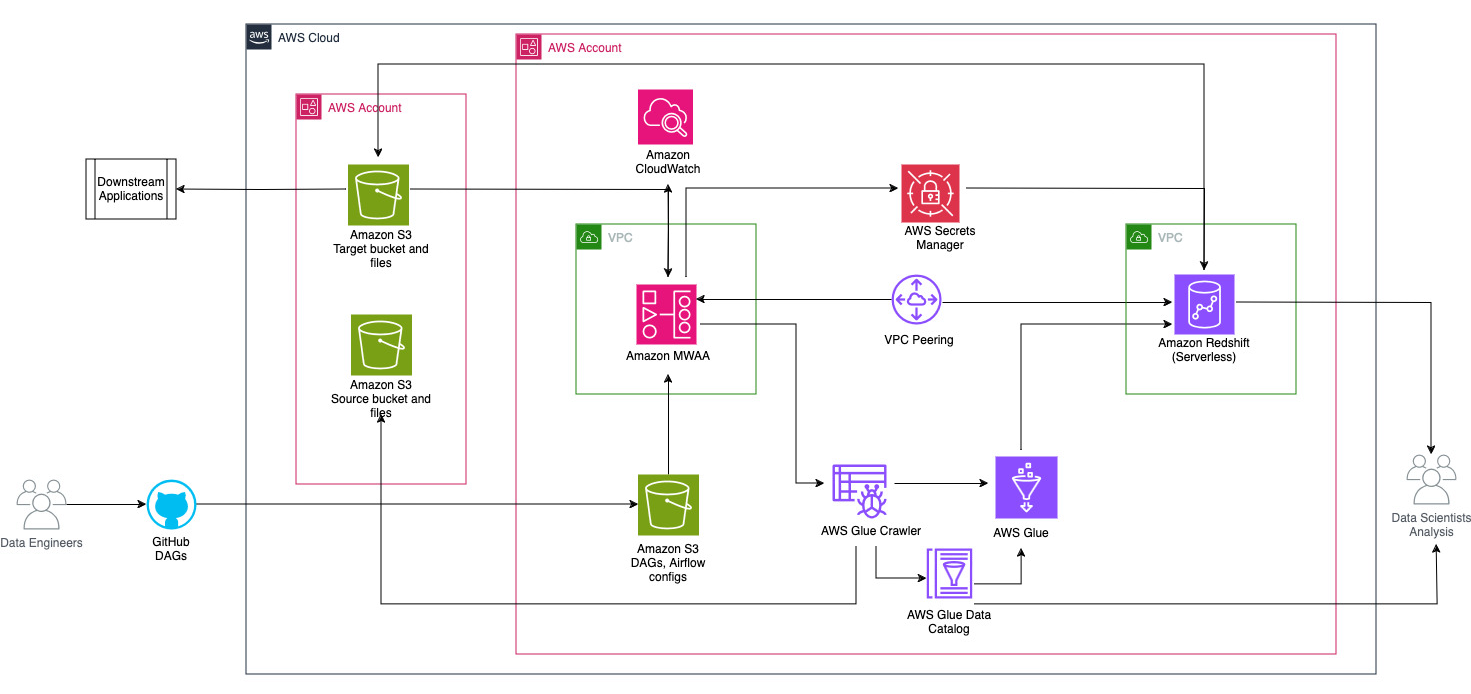
2개의 계정 사용
- A(왼쪽): Source · Target S3 bucket 소유
- B(오른쪽): 데이터 처리 작업 전담, MWAA, Glue, RedShift 소유
아키텍처 흐름
- A의 Source bucket에서 새로운 원시 데이터 탐색
- AWS Glue로 ETL 작업 호출 및 진행
- ETL 과정을 거친 데이터를 B의 Redshift에 적재
- Redshift에서 저장 프로시저, SQL 명령 실행
- A의 Target bucket으로 데이터 내보내기
- 새로운 데이터를 탐색해 ETL을 진행하고, 이를 Target bucket에 저장하는 모든 과정을 MWAA를 통해 워크플로우화함
OpenSearch
- AWS의 ElasticSearch 기반 오픈소스 검색 엔진
- 실시간 애플리케이션 모니터링, 로그 분석 및 웹 사이트 검색 등 사용
분석 도구로의 사용
- 검색 엔진이 갖는 특성을 분석에 활용 가능
- 검색 결과, 차원에 따라 분류 및 집계 가능
- 키워드, 결과 차원에 대한 스코어링 탑재
- 빠르고, 실시간 리포팅에 강함
OpenSearch vs ElasticSearch
- OpenSearch는 ElasticSearch 7.1.0의 포크
- ElasticSearch의 라이선스 분쟁으로 인해 갈라서게 됨
OpenSearch ElasticSearch 데이터 수집 - 다른 AWS 서비스와 통합 중점
- 관리형 파이프라인 제공- 다양한 데이터 유형, 구조 지원
- 대량 데이터 수집 지원보안 AWS의 강력한 보안 기능 제공 무료에서 기본 보안 기능 제공 레퍼런스 적음 많음
케이타운포유: OpenSearch 사용 추측
- 다른 AWS 서비스와의 통합을 더 중시했다면 OpenSearch 사용
Personalize
데이터를 사용하여 사용자를 위한 항목 추천을 생성하는 완전 관리형 기계 학습 서비스
Personalize 과정: 브랜디 기술블로그
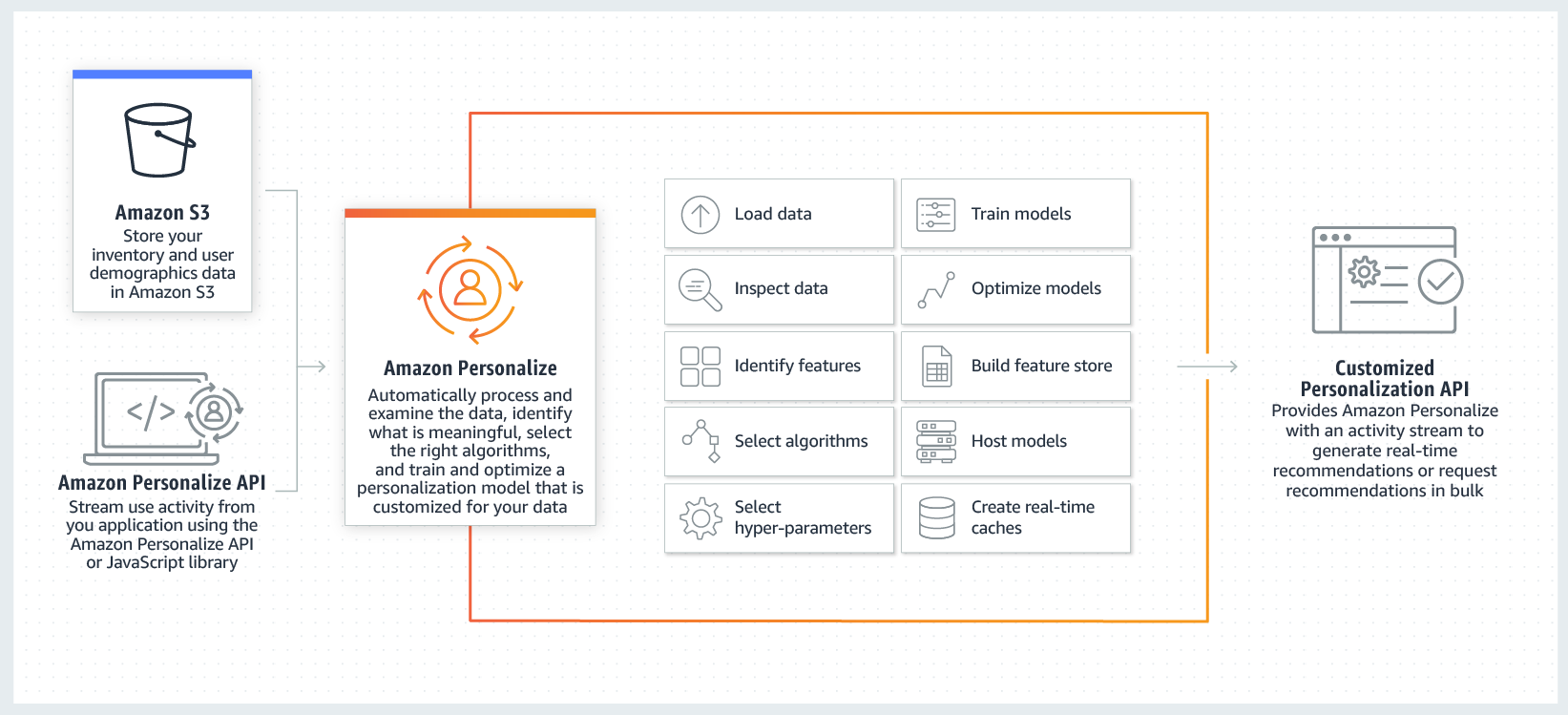
학습 데이터 준비
Personalize의 데이터 학습
- 준비한 과거 데이터를 통해 데이터 세트 생성
- 추천 레시피를 선택해 솔루션 생성
- 레시피: 개인화&추천에 사용되는 알고리즘
- 솔루션: 레시피를 사용해 교육된 모델 결과물
- 솔루션 배포를 위한 캠페인 생성
실시간 데이터 수집하기
- 이벤트 수집 SDK를 사용해 과거 + 실시간 데이터 조합으로 솔루션 제공 가능
추천 서비스의 흐름 추측
모든 서비스는 AWS의 서비스를 사용했을 것이라고 가정
- Aurora에 데이터 적재
- DMS를 활용해 Redshift로 동기화
- Glue를 통해 ETL 진행, 데이터 정제
- OpenSearch, Personalize에 정제된 데이터 연동, 개인화 구축
- 이 과정을 모두 Task로 설정 후 DAG 형성, MWAA를 통해 워크플로우화