Autodesk의 빅데이터 처리
빅데이터를 처리하는 방법, 람다 아키텍처
스트림 처리의 결과를 배치 처리로 치환하다.
AutoDesk는 실시간에 가까운 데이터 처리를 통해 비용을 최대 90% 절감하고 비즈니스 사용자를 위한 분석 기능을 개선했습니다.
💡 람다 아키텍처를 왜 사용할까요?
대용량 데이터는 일반적으로 쿼리에 많은 시간이 소요됩니다. (데이터양에 따라 조회에 몇 시간이 걸릴 수도 있습니다.)
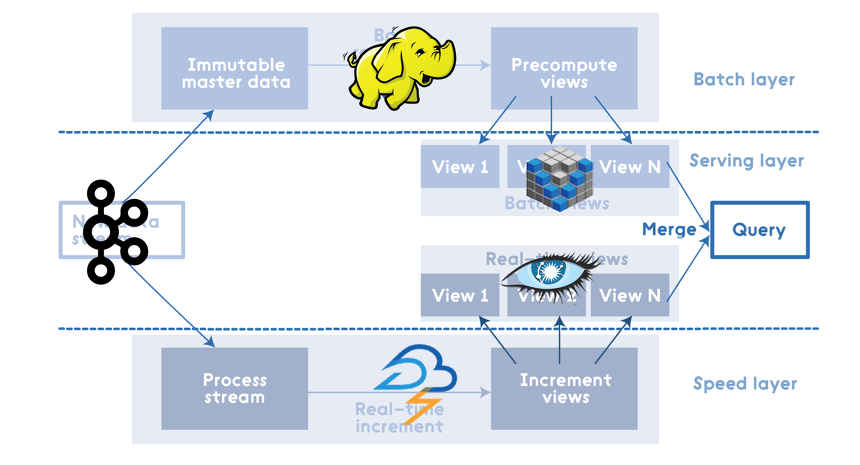
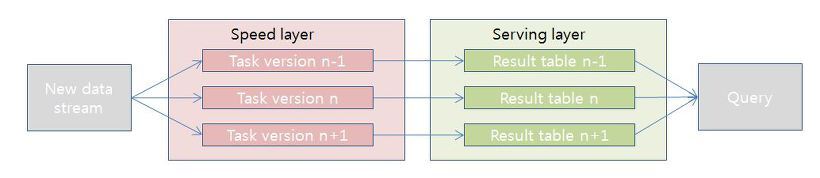
람다 아키텍처는 스피드 레이어 + 배치 레이어의 조합으로 이런 대용량 데이터에도 어느 정도의 실시간 분석을 지원해줍니다.

모든 데이터는 반드시 배치 레이어에서 처리합니다. 과거의 데이터를 장기적인 스토리지에 축적하고, 여러 번이고 다시 집계할 수 있게 합니다. 배치 레이어는 대규모 배치 처리를 실행할 수 있는 반면, 1회 처리에는 긴 시간이 걸립니다.
- 배치 처리 결과는 서빙 레이어를 통해서 접근 + 응답이 빠른 데이터베이스를 설치 ⇒ 결과를 바로 추출
- 배치 뷰: 서빙 레이어에서 얻어진 결과 → 정기적으로 업데이트되지만 실시간 정보 X
- 스트림 처리를 하기 위해 스피드 레이어를 설치 → 결과: 실시간 뷰 (배치뷰가 업데이트될 동안까지만 이용하고 오래된 데이터를 순서대로 삭제)
- 배치 뷰와 실시간 뷰 모두를 조합시키는 형태로 쿼리를 실행 → 최근 24시간의 집계 결과는 실시간 뷰를 참고하여 그 이전의 데이터에는 배치 뷰를 사용
→ 이런 과정으로 배치 처리와 스트림 처리의 결점을 모두 보완하는 람다 아키텍처를 사용하였습니다.
람다 아키텍처의 장점
- 실시간 뷰의 결과는 나중에 배치 뷰로 치환 → 스트림 처리의 결과는 일시적으로만 사용되고, 이후 배치 처리에 의해 올바른 결과를 얻습니다. 따라서 스트림처리가 정확하지 않아도 배치 처리만 안정되게 동작하면 스트림 처리를 다시 실행할 필요가 없습니다.
레이어 정리
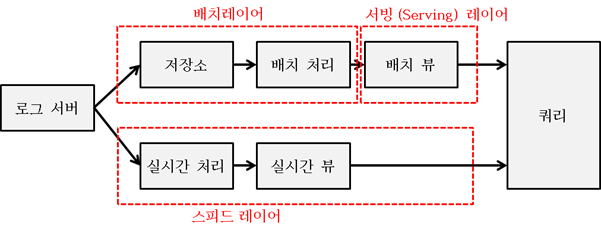
배치레이어
기존 데이터처리를 위한 배치 프로세스
- 데이터를 처리하는 단위(unit)로 데이터가 입력되면 해당 단위로 데이터 처리를 하게 됩니다. 입력되는 데이터는 마스터데이터 셋이라고 해서 저장되거나 읽기만 가능하고 변경은 안되는 immutable data set의 성질을 갖습니다.
- 단위 프로세스로 처리되기 때문에 해당 단위의 처리시에 이후에 들어온 데이터는 처리하지 못합니다. 특정단위의 배치 프로세스이기 때문에 데이터의 정합성이나 충돌, 동시성, 이상현상, 장애등에 대해서 비교적 자유로운 특성을 갖습니다.
스피드레이어
실시간 데이터를 처리하고 응답시간을 빠르게 유지 및 집계
- 배치 레이어를 사용하여 대용량 데이터 조회 속도의 이슈를 해결했지만, 배치가 도는 간격의 사이에 있는 데이터는 조회할 수 없습니다. 그래서 배치 레이어에서 생기는 이러한 갭을 채우기 위한 역할을 합니다.
- 스트림으로 들어온 데이터를 처리하기 위한 큐나 버퍼같은 구조를 사용하고 효율적 스트림처리를 위한 증분처리 방식을 사용합니다.
- 배치프로세스가 완료된 시점에는 처리된 실시간 뷰는 삭제되게 됩니다.
서빙레이어
배치에 의해서 처리된 요약 데이터를 제공
- 배치 레이어 및 스피드 레이어의 출력을 저장합니다.
- 클라이언트에서는 이 서빙 레이어에 미리 계산된 데이터를 조회하기 때문에 빠른 응답이 가능합니다.
장단점
이와 같은 3계층의 람다 아키텍처는 데이터의 정확성,일관성을 제공함과 동시에 최소의 지연으로 실시간적인 결과를 사용자에게 제공하는 장점이 있습니다.
- 배치레이어와 스피드레이어의 분리로 인한 관리포인트의 증가
- 배치처리와 실시간처리시의 개발언어나 오픈소스 인프라의 컨셉자체가 틀려 고려할 사항이 많고 이에 따라 기능이 중복되고 관리/유지보수에 많은 공수가 투입되며 복잡
아키텍처 설명
람다 아키텍쳐는 특정 솔루션에 종속적이지 않습니다. 따라서, 데이터의 처리 기법을 소개하는 레퍼런스 아키텍쳐로 이해해야 하며, 운영하는 서비스의 특성을 고려하여 솔루션을 선택하고 조합합니다.
결론적으로, 람다 아키텍처의 솔루션으로 사용될 수 있는 조합은 매우 다양합니다. 아래는 다른 솔루션 조합의 예시입니다.

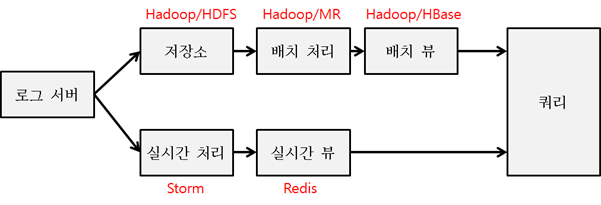 AutoDesk는 공개한 아키텍처에서 일부 내용을 비공개 혹은 표현하지 않았습니다. 따라서 작성한 아키텍처 솔루션은 일부 아키텍처로만 추측한 내용이므로 틀린 내용이 있을 수 있습니다.
AutoDesk는 공개한 아키텍처에서 일부 내용을 비공개 혹은 표현하지 않았습니다. 따라서 작성한 아키텍처 솔루션은 일부 아키텍처로만 추측한 내용이므로 틀린 내용이 있을 수 있습니다.
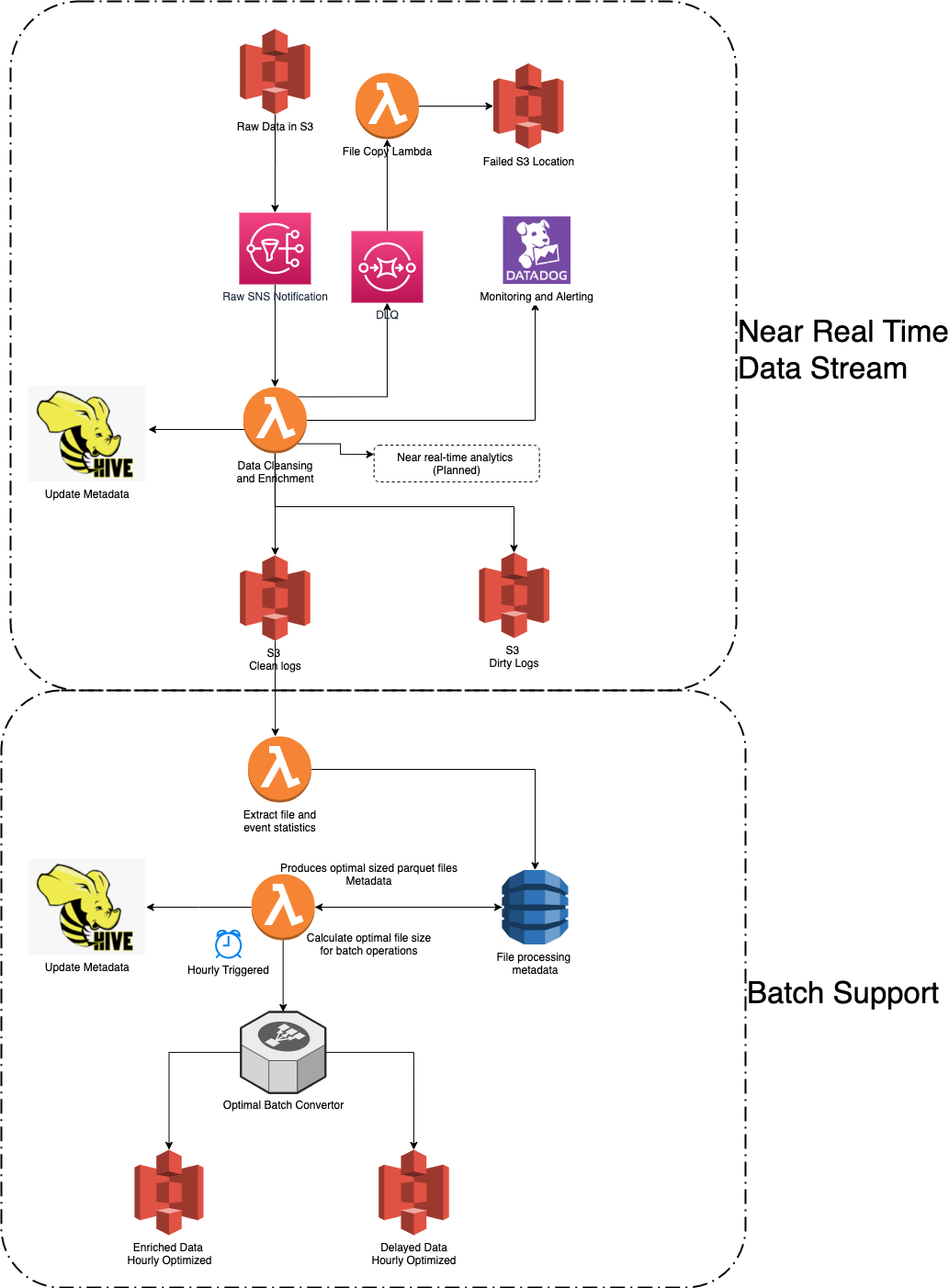
Autodesk의 실제 아키텍처
저장소(=마스터 데이터 셋)
대량의 데이터를 저비용으로, 안정성 있게 (유실이 없게) 저장할 수 있는 것이 필요합니다. 그리고 이런 대량의 데이터를 배치로 처리할 때 되도록이면 빠른 시간내에 복잡한 알고리즘을 적용해서 계산할 수 있는 계층이 필요합니다.
👉Autodesk는 이를 위해 AWS S3를 사용하였습니다.
스피드 레이어
실시간 처리
실시간 처리는 복잡한 알고리즘을 빠르게 데이터를 처리할 수 있는 솔루션이 필요한데, 대표적으로 Apache Storm등이 있으며, 이 아키텍처에서는 AWS Lambda 함수를 통해 처리될 것으로 보입니다.
실시간 뷰
빠른 읽기와 쓰기를 지원해야 하기 때문에, Redis와 같은 In-memory 기반의 NoSQL이 적절하게 추천됩니다.
👉Autodesk에서는 실시간 뷰로 dynamoDB를 사용하였습니다.
배치 레이어
배치 처리
Hive는 MapReduce를 이용해 데이터를 처리하는데, 이는 람다 아키텍처의 배치 레이어에서 대규모 데이터셋을 처리하는 데 사용될 수 있습니다. 이 과정에서 Hive는 데이터를 집계, 변환, 로딩하는 등의 배치 작업을 수행합니다. 메타데이터를 업데이트하기 위해 Hive가 사용되며, 이는 배치 레이어가 데이터를 관리하고 처리하는 역할의 일부일 수 있습니다.
Optimal Batch Converter (AWS Glue와 같은 AWS 서비스나 다른 서드파티가 사용되었을 수 있습니다.)
배치 뷰
아키텍처에 특정 기술로 명시적으로 표시되지 않았지만, 데이터 웨어하우스(AWS Redshift) 나 Hadoop/HDFS 또는 Amazon S3와 같은 파일 저장 시스템에 저장될 수 있습니다.
→ 해당 아키텍처에서는 전반적으로 이벤트 기반의 서버리스 서비스인 AWS Lambda를 광범위하게 활용합니다.
개선 방안
람다 아키텍처의 재구성
RDBMS를 활용한 유연성 증대 방안
이러한 람다 아키텍쳐는 대용량 데이터 처리와 실시간 정보 제공을 위한 장점을 가지고 있음에도 불구하고 대부분 하둡이나 NOSQL등의 솔루션을 조합해서 구현하는 경우가 대부분이기 때문에, 유연성 측면에서 문제점을 가지고 있습니다.
🔑 예시
배치 뷰를 HBase를 사용하고, 실시간 뷰를 Redis를 사용할 경우, 상호 솔루션간 데이터 조인이 불가능할 뿐더러, 인덱스나 조인,그룹핑, 소팅 등이 어렵습니다. 이러한 기능이 필요하다면 각각 배치 처리와 실시간 처리 단계에 추가적으로 로직을 추가해서 새로운 뷰를 만들어야 합니다.
이를 더 쉽게 설명하면, 일반적인 NoSQL은 키-밸류 스토어의 개념을 가지고 있습니다.

일별 배치로 생성된 이벤트 데이터 테이블
그래서 위와 같은 테이블이 생성되었다 하더라도, 특정 컬럼 별로 데이터를 소팅해서 보여줄 수 없습니다. 만약 소팅된 데이터를 표현하고자 한다면, 소팅이 된 테이블 뷰를 별도로 생성해야 합니다.
→ 이런 문제점을 보강하기 위해서는 실시간 뷰와 배치 뷰 부분을 RDBMS를 사용하는 것을 고려해볼 수 있습니다. 쿼리에 특화된 OLAP 데이터 베이스를 활용하는 방법도 있고, 또는 HP Vertica 등을 활용할 수 있습니다. (HP Vertica는 SQL을 지원하지만, 전통적인 RDBMS가 데이터를 행 단위로 처리하는데 반하여, Vertica는 데이터를 열 단위로 처리해서 통계나 쿼리에 성능이 매우 뛰어납니다. 유료이지만 1테라까지는 무료로 사용할 수 있으니 뷰 테이블 용도 정도로 사용하는데는 크게 문제가 없습니다.)
카파 아키텍처 선택
- 스피드 레이어와 배치 레이어가 모두 똑같은 처리를 구현하고 있으므로 중복된 비즈니스 로직 및 두 경로의 아키텍처 관리에 따른 복잡성이 발생합니다.
→ 이 때문에 람다 아키텍쳐를 단순화한 ‘카파 아키텍쳐(Kappa architercutre)‘를 선택하기도 합니다.
1. Near Real Time Data Stream
실시간에 가까운 데이터 스트림 (✍️ 세은 어진)
2️⃣ Part 1(Near Real Time Data Stream) 목차
- 아키텍처 흐름 설명
- 실시간 처리를 위한 Lambda 사용
- 데이터 레이크로서의 S3 사용 a. 데이터 웨어하우스와 데이터 레이크 비교
- SQS(DLQ)
- SNS
- DataDog
- Apache Hive
아키텍처
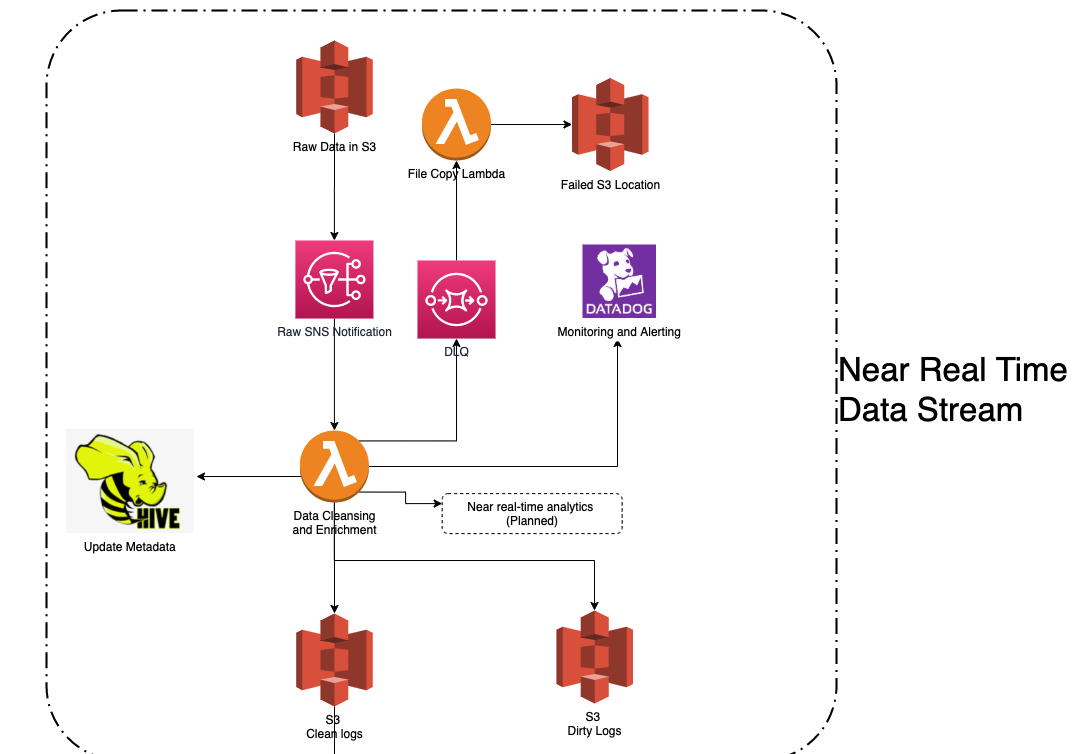
최대 10배 이상으로 급증하는 수신 데이터를 처리할 수 있도록 기존 시스템을 개선 + 데이터 처리 속도와 가용성을 1시간으로 개선하고 처리 비용을 70% 줄이기
- 높은 처리량, 짧은 지연 시간, 실시간에 가까운 처리를 달성하기 위해 Autodesk는 Amazon DynamoDB를 통합했습니다. ADP는 Amazon DynamoDB를 사용하여 수천 건의 동시 요청을 수밀리초 내에 처리합니다. 또한 Amazon Simple Storage Service(S3)를 사용하여 안전한 데이터 레이크를 구축하고 높은 데이터 가용성을 달성했습니다.
흐름
1 . Raw Data 저장: Amazon S3에 원시 데이터가 저장됩니다.
a . 원시 데이터는 Amazon S3에 저장됩니다. S3는 인터넷 스토리지 서비스로, 대량의 데이터를 안전하게 저장하고 검색할 수 있는 데이터 레이크의 역할을 합니다.
b . 데이터 레이크는 원시 데이터를 그대로 저장해두는 공간으로, 데이터 웨어하우스와는 달리 구조화하지 않은 상태로 데이터를 저장합니다.

2 . SNS 알림: Amazon SNS를 통해 원시 SNS 알림이 발송됩니다.
a . 원시 데이터가 S3에 저장되면, Amazon SNS를 통해 알림이 발생합니다.
b . SNS는 분산 애플리케이션, 마이크로서비스, 서버리스 애플리케이션 등에 대한 메시지 전달을 담당합니다.

3 . 데이터 정제 및 보강: Lambda가 데이터 정제와 보강을 담당합니다.
a . 만약, 데이터 정제 및 보강이 실패한다면 DLQ에서 해당 이슈를 캐치합니다.
b . DLQ에서 문제가 된 데이터를 File Copy Lambda로 전달합니다.
c . File Copy Lambda는 데이터를 복사하여 Failed S3 Location에 저장합니다.
d . Failed S3 Location에 저장된 데이터들은 나중에 다시 검토하거나 추가적인 조치를 취할 수 있습니다.
💡 기존의 배치 처리 모델은 일정한 주기로 데이터를 처리하는 방식에서 AWS Lambda를 사용하여 데이터가 수신되는 즉시 해당 데이터를 처리예약된 시간에 데이터 처리를 기다리지 않고도 데이터를 실시간으로 처리할 수 있게 해주는 효과를 냅니다.
Lambda 함수가 이벤트를 트리거하면 DynamoDB는 이에 대한 신속하고 효율적인 응답을 제공하여 동시 다발적인 요청에 효과적으로 대응합니다.
4 . Update Metadata
a . Hive를 사용하여 해당 데이터와 관련된 메타데이터 업데이트를 진행합니다.
b . 메타데이터 업데이트는 데이터의 구조, 스키마, 타입 등의 정보를 정리하고, 데이터의 검색 및 관리를 용이하게 하기 위한 목적으로 이루어집니다.
💡 복잡한 MapReduce 작업을 SQL-like 쿼리로 간소화하여 대용량 데이터의 처리를 쉽게 해주는 데이터 웨어하우스 도구입니다.
Hive는 Hadoop 클러스터 위에서 동작하므로 Hadoop의 확장성과 안정성을 그대로 활용합니다. 대용량 데이터를 처리하는 데에는 Hive가 더 적합합니다.

5 . 모니터링 및 경고: 전체 시스템은 DataDog를 통해 모니터링되며, 이상 징후나 오류에 대해 경고해줍니다.
a . AWS 서비스들과 연동된 DataDog을 통해 전체 데이터 처리 과정을 모니터링 합니다.
b. 이를 통해 시스템의 정상 작동 상태를 유지하고, 문제가 발생하면 신속하게 대응할 수 있습니다.

6 . 로그 처리: 처리된 데이터 로그는 ‘Clean Logs’ S3에 저장되고, 문제가 있는 로그는 ‘Dirty Logs’로 분류되어 별도로 관리됩니다.
a .정제된 데이터는 ‘clean logs’로, 정제되지 못한 데이터는 ‘dirty logs’로 분류되어 다시 S3에 저장됩니다.
💡 이렇게 데이터 레이크에 저장된 로그 데이터는 필요에 따라 추출, 변환, 로드(ETL) 작업을 거쳐 분석 및 처리됩니다.


Lambda
실시간에 가까운 처리를 위해 람다를 어떻게 사용했는가
- 데이터가 S3에 도착하는 즉시 수집한 데이터를 자동으로 정리하고 보강하는 Lambda 함수를 트리거하여 실행합니다.
- Lambda의 특성상 위 과정은 처리를 위한 사전 설정된 서버가 없어도 이루어지며, 필요한 컴퓨팅 리소스를 동적으로 할당받아 사용합니다.
⇒ 이를 통해 데이터 처리 시간을 단축하고, 처리량이 갑자기 증가해도 유연하게 대응할 수 있습니다.
S3
데이터 레이크로서 어떻게 활용했는가
데이터 웨어하우스와 데이터 레이크 비교
데이터 레이크 데이터 웨어하우스 데이터 형식 원시 데이터 및 비정형 데이터와 같은 모든 구조의 데이터 저장이 가능합니다. 구조화된 형식으로 저장합니다. 유연성 다양한 데이터 분석 도구와 호환됩니다. 더 큰 유연성 제공합니다. 특정 스키마에 맞춰진 쿼리를 위해 최적화된 구조입니다. 처리 목적 대규모 데이터 처리, 복잡한 분석, 데이터 마이닝, 머신 러닝, etc… 비지니스 인텔리전스와 같은 정형화된 보고서 분석 성능 다양하고 복잡한 분석이 가능합니다. 종종 처리 속도가 느릴 수도 있습니다. 빠른 읽기 및 쿼리 성능을 위해 최적화되어 있습니다. 비용 더 낮은 비용으로 더 많은 스토리지 볼륨을 확보할 수 있습니다. 다양한 형태의 데이터 저장: S3에는 다양한 소스로부터 수집된 원시 데이터가 저장됩니다. 이 데이터는 구조화되지 않은 로그 파일, JSON, CSV 등 다양한 형식을 가질 수 있습니다.
유연한 데이터 접근 및 분석: S3에 저장된 데이터는 필요에 따라 다른 AWS 서비스(ex. Lambda, Apache Hive)에 의해 접근되고 처리됩니다. 이를 통해 데이터를 정제하고, 보강하며, 분석에 필요한 형태로 변환합니다.
대규모 데이터 처리: 데이터 레이크로서 S3는 대용량의 데이터를 저장하고 관리할 수 있는 능력을 가지고 있습니다. 따라서 실시간에 가까운 데이터 스트리밍 및 분석이 가능합니다.
SQS (DLQ)
배달 못한 편지 대기열, Dead Letter Queue
- SQS : 완전 관리형 메시지 대기열 서비스입니다. 서버리스 애플리케이션 간에 메시지를 안전하게 전송, 저장 및 수신을 할 수 있게 해줍니다. SQS가 Lambda 함수의 트리거로 설정되는 것이 일반적입니다.
- Dead Letter Queue (DLQ) : SQS의 구성요소로, SQS 메시지 큐에서 처리되지 못한 메시지를 보관하는 곳입니다. SQS는 메시지를 서비스 간에 전달하는 역할을 하는데, 여기서 메시지가 정상적으로 처리되지 않을 경우(예: 오류 발생, 처리 시간 초과 등), 해당 메시지는 DLQ로 이동합니다. DLQ를 사용하면 실패한 메시지를 분리하여 관리할 수 있으며, 이를 통해 문제 해결과 재처리를 용이하게 할 수 있습니다. DLQ는 시스템의 안정성과 신뢰성을 높이는 데 중요한 역할을 합니다.
SNS
데이터 처리 과정 중에 발생하는 중요한 이벤트들에 대해 알림을 제공하는 역할
- Raw data가 S3에 성공적으로 저장되었을 때, 이 정보를 Lambda 함수에 알려주고 있습니다.
DataDog
대규모 애플리케이션 및 인프라를 위한 SaaS 기반 모니터링 및 분석 플랫폼
- 클라우드 기반의 모니터링 서비스로, 시스템의 성능, 상태, 오류 등을 실시간으로 추적할 수 있습니다.
- 이 시스템에서는 데이터의 정제 및 보강 과정을 DataDog를 사용하여 실시간으로 모니터링 하고 있습니다.
- 문제 발생시 DataDog는 즉각적인 경고나 알림을 제공하여 시스템 관리자나 개발자가 빠르게 대응할 수 있도록 해줍니다. (ex. 데이터 처리 지연, 시스템 성능 저하, 프로세스 중단, etc)
- 데이터 처리 과정의 안정성과 효율성을 보장하는 데 중요한 역할을 수행합니다.
Apache Hive
Hadoop 기반 데이터 웨어하우스 소프트웨어로, 대규모 데이터셋을 관리하고 분석하는 데 사용
- 이 시스템에서 Hive는 메타데이터 업데이트를 위해 사용되고 있습니다.
- Hive는 SQL과 유사한 HQL(Hive Query Language)을 제공하여, 사용자가 복잡한 데이터 처리 작업을 쉽게 수행할 수 있도록 합니다.
- 메타데이터 : 다른 데이터를 정의하고 기술하는 데이터입니다. 메타데이터를 업데이트함으로써, 데이터가 더 잘 조직되고 검색이 용이해지며, 추후 데이터의 관리 및 사용에 있어서 중요한 역할을 합니다.
- 왜 Hive인지
- SQL과 유사한 쿼리 언어: Hive는 SQL과 유사한 HQL을 사용하여 데이터에 쉽게 접근하고 분석할 수 있습니다. 익숙한 언어를 사용하여 빅데이터를 다룰 수 있게 해줍니다.
- 데이터 웨어하우스에 최적화: Hive는 데이터 웨어하우스를 위해 설계되었으며, 대규모 데이터의 관리 및 쿼리에 효과적입니다.
- 참고 ) https://velog.io/@anjinwoong/Hive-Hive-의-특징
2. Batch Support
배치 지원 (✍️ 현정 희진 유빈)
2️⃣ Part 2(Batch Support) 목차
- ETL 소개
- Lambda 소개
- 배치 처리 모델(이전 아키텍처) vs. 이벤트 기반 모델(Lambda)
- 아키텍처 설명
- Lambda + DynamoDB → ETL 처리 과정
- Hive (Hadoop + Hive)
- 심화 내용 + 생각해 본 내용
ETL
- Extract(추출), Transform(변환, 가공), Load(로드)의 머리 글자를 딴 것 입니다.
- 추출, 전환, 적재(ETL)는 다양한 소스의 데이터를 데이터 웨어하우스라고 부르는 대형 중앙 집중식 리포지토리에 결합하는 과정입니다.
- ETL은 원시 데이터를 정리 및 구성해서 스토리지, 데이터 분석, 기계 학습(ML)용으로 준비하기 위한 비즈니스 규칙 세트입니다.
- 사용자는 데이터 분석(비즈니스 의사 결정의 결과 예측, 보고서 및 대시보드 생성, 운영 비효율성 저감 등)을 통해 특정 비즈니스 인텔리전스 요구 사항을 해결할 수 있습니다.
추출(Extract)
- 데이터 추출은 하나 이상의 여러 소스에서 데이터를 가져오는 작업입니다.
- 추출 방식에 있어서 배치 ETL와 실시간 ETL(스트리밍 ETL)의 두 가지 범주로 나눌 수 있습니다.
- 배치 ETL은 지정된 시간 간격으로만 소스에서 데이터를 추출하고, 스트리밍 ETL은 데이터 추출 가능 즉시 ETL 파이프라인을 통과합니다.
변환(Transform)
- ETL을 수행하기 위해 비정형 데이터를 정형으로 재정렬하거나, 추출한 데이터를 몇 개의 필드로만 제한 하는 등의 변경 작업이 발생합니다.
로드(Load)
- 위 프로세스를 통해 데이터를 준비했다면 어딘가의 데이터 저장소에 로드 해야합니다.
- 일반적으로 데이터베이스는 BI 및 분석 시스템과 함께 작동하도록 설계된 중앙 집중식 레포지토리인 통합 데이터 웨어하우스입니다.
ETL이란 무엇인가요? - 추출, 전환, 적재 설명 - AWS
Lambda
Lambda는요 .. !
- 서버를 프로비저닝 또는 관리하지 않고도 실제로 모든 유형의 애플리케이션과 백엔드 서비스에 대한 코드를 실행할 수 있는 이벤트 중심의 서버리스 컴퓨팅 서비스입니다.
- 여기서
서버리스 컴퓨팅이란 서버의 설정과 관리 없이 백엔드 서비스를 운영할 수 있게 해주는 클라우드 컴퓨팅 실행 모델입니다. 사용자는 코드 작성에만 집중하고, 나머지 인프라 관리는 AWS가 담당하게 됩니다. 이는 개발자가 인프라에 대한 고민 없이, 더 빠르고 효율적으로 애플리케이션을 개발하고 배포할 수 있게 해줍니다.
- 여기서
- Lambda를 사용하면 사용자 지정 로직을 통해 다른 AWS 서비스를 확장하거나, AWS 규모, 성능 및 보안으로 작동하는 자체 백엔드 서비스를 만들 수 있습니다.
- 계속 실행시키는 작업 대신 특정한 시기에만 실행시키는 경우에 Lambda를 사용하면 유용합니다.
- 빠르게 확장하고 수요가 없을 때는 0으로 축소해야 하는 애플리케이션 시나리오에 이상적인 컴퓨팅 서비스입니다.
이번 아키텍처에서는 파일 extract 와 이벤트 통계를 위해 사용합니다. 자세한 내용은 아래 “이 목차” 에서 확인할 수 있습니다.
Lambda를 언제 사용할까요?
- 복잡도가 낮은 코드: Lambda는 최소한의 변수와 타사 종속성을 사용하여 코드를 실행하기 위한 완벽한 선택입니다. 복잡도가 낮은 코드가 포함된 쉬운 작업을 간소화된 방식으로 처리할 수 있습니다.
- 실행 시간 단축: Lambda는 가끔식 발생하는 작업을 실행하는 데 적합하며 몇 분 내에 실행될 수 있습니다.
- 드문 트래픽: 기업은 서버가 유휴 상태일 때 이를 싫어하며 여전히 비용을 지불해야 합니다. 기능별 지불 모델은 컴퓨팅 비용을 크게 절감하는 데 도움이 될 수 있습니다.
- 실시간 처리: AWS Kinesis와 함께 사용되는 Lambda는 실시간 배치 처리에 가장 적합합니다.
- 예약된 CRON 작업: AWS Lambda 기능은 예약된 이벤트가 정해진 예약 시간에 작동하도록 하는 데 적합합니다.
배치 처리 모델(이전 아키텍처) vs. 이벤트 기반 모델(Lambda)
- 실행 방식:
- 배치 처리 모델: 일정한 주기(일반적으로 시간 단위 또는 일 단위)로 데이터를 일괄적으로 처리하는 방식입니다. 데이터가 쌓이면 주기적으로 일괄 처리 작업이 실행되어 데이터를 분석하고 결과를 생성합니다.
- 이벤트 기반 모델 (Lambda): 데이터 이벤트가 발생할 때마다 즉각적으로 반응하는 방식입니다. 특정 이벤트(예: 데이터 도착, 파일 업로드 등)가 발생하면 AWS Lambda 함수가 트리거되어 이벤트를 처리하고 필요한 작업을 수행합니다.
- 실시간 처리:
- 배치 처리 모델: 주기적인 일괄 처리로 인해 데이터 분석 결과가 일정 시간에 한 번씩 생성되므로 실시간 처리에는 적합하지 않습니다.
- 이벤트 기반 모델 (Lambda): 이벤트가 발생하자마자 Lambda 함수가 실행되므로 거의 실시간으로 데이터를 처리할 수 있습니다.
- 데이터 처리 지연:
- 배치 처리 모델: 일정한 주기에 따라 데이터 처리를 수행하므로, 데이터 수신부터 결과 생성까지의 시간이 상대적으로 길 수 있습니다.
- 이벤트 기반 모델 (Lambda): 이벤트가 발생하자마자 처리되므로 거의 실시간으로 데이터를 처리하며, 지연 시간이 짧습니다.
아키텍처 설명
Batch: 데이터를 실시간으로 처리하는게 아니라, 일괄적으로 모아서 처리하는 작업
💡 배치 처리 모델 → 이벤트 기반 모델 (Lambda) - Autodesk는 예약된 시간에 데이터를 처리하면서 분석을 지연시키는 것이 아니라, 수신되는 데이터를 즉시 처리할 수 있게 되었습니다.
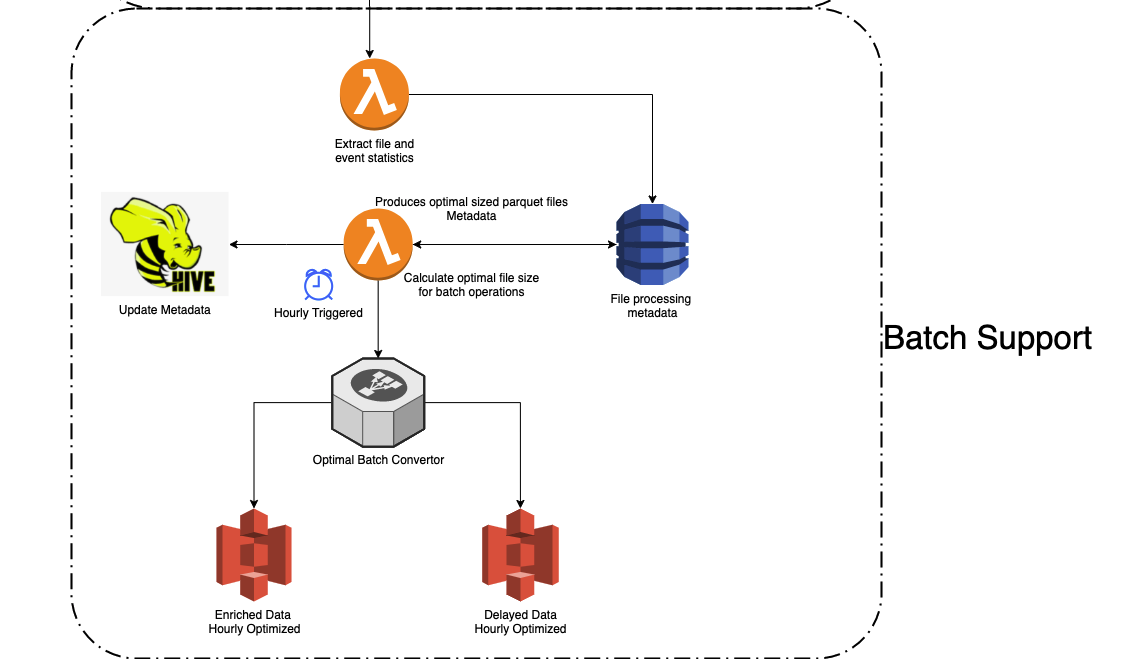
Batch Support에서는 위에서 설명한 아키텍처의 배치 레이어에 대해 다룹니다.
1 과정에서 S3에 저장한 clean logs(정제된 데이터)에서 파일과 이벤트 통계를 람다로 extract 하고, 그 데이터를 DynamoDB에 적재합니다.
DynamoDB는 하단 람다와 함께 적절한 사이즈의 파케이(= 하둡에서 칼럼방식으로 저장하는 저장 포맷) 파일 메타데이터로 제공합니다. 람다는 매시간 Hive에 메타데이터를 업로드하는 함수를 호출합니다.
람다는 최적의 배치 변환기를 통해 매시간마다 최적화 된 보강 데이터 / 지연 데이터를 S3에 저장합니다. 배치 레이어의 저장소에는 가공전의 원본 데이터를 모두 저장합니다. 데이터가 처리된 후에도 저장소에 데이터를 삭제하지 않습니다.
이렇게 원본 데이터를 저장함으로써, 배치 뷰의 데이터가 잘못 계산되었거나 유실되었을때, 복구가 가능하고, 현재 데이터 분석에서 없었던 새로운 뷰(통계)를 제공하고자 할 때 기존의 원본 데이터를 가지고 있음으로써, 기존 데이터에 대해서도 새로운 뷰의 통계 분석이 가능하게 됩니다.
Lambda + DynamoDB → ETL 처리 과정
이번 아키텍처에서는 파일 extract 와 이벤트 통계를 위해 Lambda를 사용합니다.
이때 DynamoDB와 연동하여 ETL(추출 변환 로드) 과정을 진행합니다. DB 테이블의 데이터 변경에 대해 변환 작업을 수행할 수 있습니다.
- DynamoDB란?
- AWS에서 제공하는 서버리스 기반 Key-Value NoSQL 데이터베이스입니다.
Serverless Batch Processing
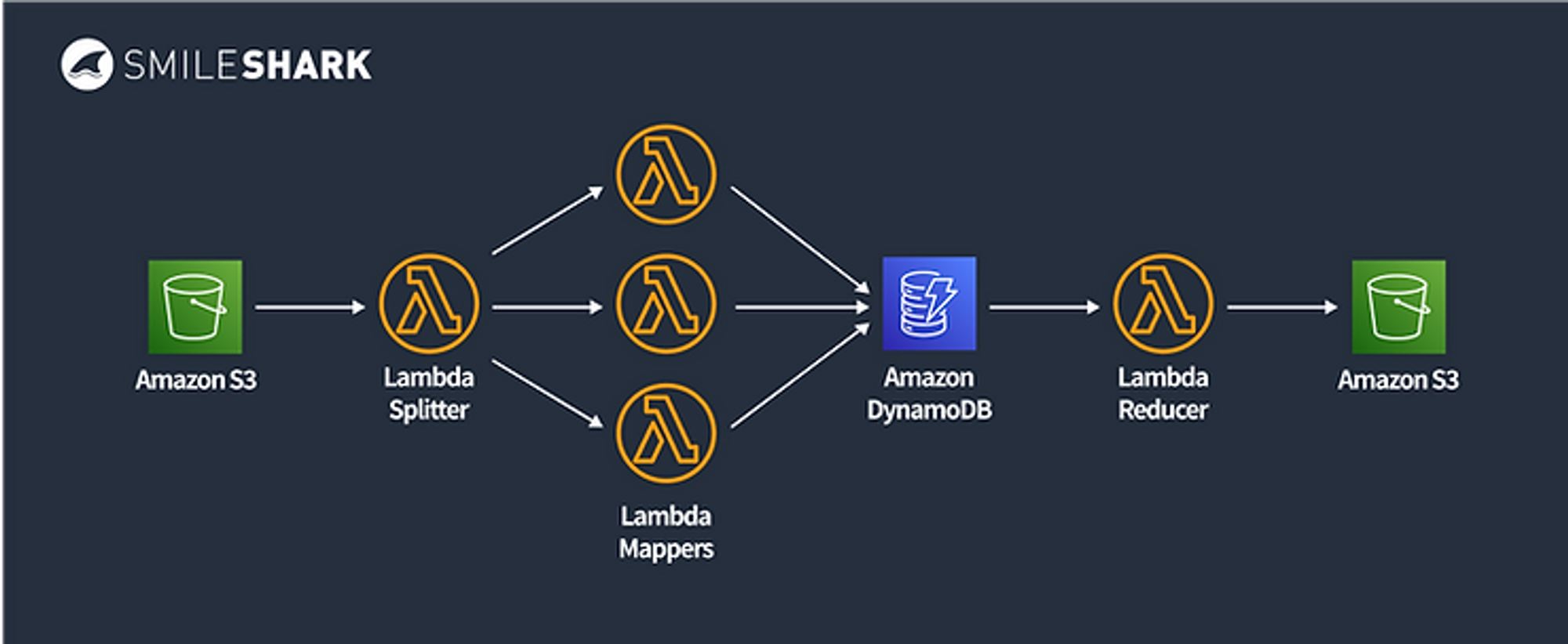
S3에 어떤 오브젝트가 들어왔을 경우Lambda Splitter가 Mapper에 작업을 분배합니다.- Mapper들은 작업이 끝난 후
DynamoDB에 저장됩니다. Lambda Reducer가S3로 다시 아웃풋합니다.

Pull Event Type(Model)
Pull 이벤트 모델에서는 AWS Lambda가 직접 데이터를 생성하는 것이 아니라, 데이터 소스에서 Lambda 함수를 트리거하도록 허용하는 방식입니다.
대표적인 예시로는 Amazon Simple Queue Service (SQS), Amazon Simple Notification Service (SNS), Amazon EventBridge (CloudWatch Events) 가 있습니다.
Pull Event 모델을 사용하면 데이터 소스에서 데이터가 생성되는 시점이나 이벤트가 발생하는 시점에 따라 Lambda 함수를 트리거할 수 있어서 이벤트 중심 아키텍처를 구성하는 데 효과적입니다.
실시간에 가까운 처리에서 S3 clean logs 에 저장된 데이터를 Extract합니다.
Hive
Apache Hive
- Hive는 Hadoop 에코시스템 중에서 데이터를 모델링하고 프로세싱하는 경우 가장 많이 사용하는 데이터 웨어하우징용 솔루션입니다.
- Hadoop을 기반으로 빌드되었기 때문에 페타바이트 규모의 데이터를 신속하게 처리할 수 있습니다.
- Apache Hadoop Distributed File System(HDFS)에서 추출한 대용량 데이터 세트를 읽고, 쓰고, 관리하도록 설계된 오픈 소스 데이터 웨어하우스 소프트웨어입니다.
- 사용자가 SQL을 사용하여 페타바이트 데이터를 읽고 쓰고 관리할 수 있도록 합니다. SQL과 유사한 인터페이스로 Apache Tez 또는 MapReduce를 사용하여 대규모 데이터 세트를 쿼리할 수 있습니다.
- 광범위한 Apache Hive 문서 및 지속적 업데이트를 통해 쉽게 액세스할 수 있는 방식으로 계속해서 데이터 처리를 혁신합니다.
데이터양에 좌우되지 않는 쿼리 엔진
- Hadoop 상의 분산 애플리케이션은 애초에 높은 확장성과 내결함성을 목표로 설계되었습니다.
- 수천 대나 되는 하드웨어를 이용하는 것이 전제입니다.
- Hive도 연장 선상에 있습니다 → 대규모 배치 처리를 꾸준히 실시합니다.
- 텍스트 데이터 가공, 열 지향 스토리지를 만드는 등의 무거운 처리에 적합합니다.
- 대화성이라기 보다는 안전성에 장점이 있습니다.
Hive는 배치 처리 툴이라기 보다는 데이터 집계를 위한 쿼리 엔진입니다. 이 아키텍처에서는 하둡과 함께 사용된 것으로 추정됩니다.
Hive 동작 방식
- Hive는 SQL에 익숙하고 프로그래머가 아닌 사람도 HiveQL이라는 SQL과 유사한 인터페이스를 사용하여 페타바이트 규모의 데이터를 처리할 수 있도록 만들어졌습니다.
- 기존의 관계형 데이터베이스는 중소 규모의 데이터 세트에 대한 대화형 쿼리를 위해 설계되었으므로 대규모 데이터 세트를 제대로 처리하지 못합니다.
- Hive는 대신 배치 처리를 사용하므로 대규모 분산 데이터베이스에서 신속하게 작동합니다.
- Hive는 HiveQL 쿼리를 MapReduce 또는 Tez 작업으로 변환하여 Apache Hadoop의 분산 작업 예약 프레임워크인 YARN(Yet Another Resource Negotiator)에서 실행됩니다.
- Hadoop 분산 파일 시스템(HDFS) 또는 Amazon S3와 같은 분산 스토리지 솔루션에 저장된 데이터를 쿼리합니다.
- 데이터베이스 및 테이블 메타데이터를 메타스토어에 저장합니다. 메타스토어는 데이터를 쉽게 추상화하고 검색할 수 있는 데이터베이스 또는 파일 기반 스토어입니다.
심화+고민해 본 부분) Spark & Hadoop을 사용하지 않은 이유?
Hadoop+Spark 조합이 보편적입니다. 그런데 이를 사용하지 않고 Hadoop+Hive를 사용한 이유는 무엇일까요?
→ Hive는 데이터 처리를 위한 대규모 배치 처리 구조를 지원하는데, 이를 위해 사용했을 것으로 추측됩니다.
→ Spark는 일반적으로 데이터를 실시간으로 처리합니다.
Hive
- Hive는 데이터베이스가 아닌 데이터 처리를 위한 배치 처리 구조입니다.
- 읽어 들이는 데이터의 양을 의식하면서 쿼리를 작성해야 원하는 성능이 나올 수 있습니다.
- Hive는 대용량 데이터 처리에 유용하고 분산 환경을 지원합니다.
- 메타정보를 보관하는 메타 스토어를 가지고 있어, 메타데이터 관리에 용이합니다. → 메타데이터를 통한 데이터 분석 가능
심화 내용 + 생각해 본 내용
1. 어떻게 수신되는 데이터를 즉시 처리할 수 있도록 하였는가?
- AWS는 배치 처리 모델을 기반으로 하던 ADP를 AWS Lambda에서 실행되는 이벤트 기반 모델로 전환하는데 도움을 주었습니다.
- 그 후 Autodesk는 예약된 시간에 데이터를 처리하면서 분석을 지연시키는 것이 아니라 수신되는 데이터를 즉시 처리할 수 있게 되었습니다.
- ETL 집계를 자동화 해주고, 거의 실시간으로 처리됩니다.
2. 어떻게 수천 건의 동시 요청을 수 밀리초 내에 처리할 수 있는가?
Apache Hive를 이용한 빠른 데이터 처리가 있었습니다.
DynamoDB는 읽기 속도가 RDBMS보다 빠른 분산형 및 관리형 NoSQL 데이터베이스로서, 대규모의 동시 요청을 효과적으로 처리하기 위해 설계되었기 때문에 이를 사용한 게 유용하였다고 생각됩니다.
3. Apache Hive: Hive를 어떤 용도로 사용했는가?
Apache Hive는 Apache Hadoop을 기반으로 빌드되었기 때문에 페타바이트 규모의 데이터를 신속하게 처리할 수 있었습니다.
또한, SQL과 유사한 인터페이스로 Apache Tez 또는 MapReduce를 사용하여 대규모 데이터 세트를 쿼리할 수 있습니다.
맵리듀스 프로그래밍 모델은 Map과 Reduce라는 크게 2가지 단계로 데이터를 처리합니다. 맵은 입력 파일을 한 줄씩 읽어 데이터를
변형(Transformation)하며 리듀스는 맵의 결과 데이터를집계(Aggregation)합니다.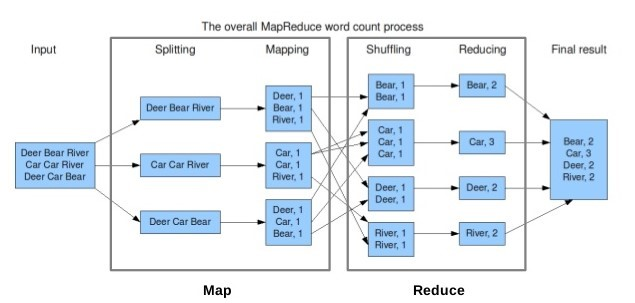
대규모 분산 처리를 위한 용도로 사용했을 것이라 추측됩니다.
Archive
→ 실시간성 데이터에 대한 니즈가 증가하면서 일반적으로 하둡만으로 처리하기 어려워졌고, Hadoop + Spark 조합으로 많이 사용한다.
Spark
- Spark는 분산 시스템을 사용한 프로그래밍 환경으로 대량의 메모리를 활용하여 고속화를 실현하는 것입니다.
- 인메모리 상에서 동작하기 때문에 반복적인 처리가 필요한 작업에서 속도가 하둡보다 1000배 이상 빠릅니다.
- Spark는 Hadoop이 아니라 MapReduce를 대체합니다.
- Spark 상의 데이터 처리는 자바 등의 스크립트 언어를 사용할 수 있습니다.
- Spark는 분산 시스템을 사용한 프로그래밍 환경으로 대량의 메모리를 활용하여 고속화를 실현하는 것입니다.